
[论文阅读]GPU-accelerated Database Systems Survey and Open Challenges
GPU与CPU
显卡通过 PCIExpress 总线连接到主机系统
总线带宽低(比主机内存慢2-3倍),所以数据传输是瓶颈。GPU有多个多处理器,每个多处理器里有成百上千个简单核心,适合并行计算,但不适合复杂控制逻辑(比如分支太多会慢)。
编程模式:
编程GPU用“内核模型”:主机代码管理GPU,内核是并行单元,一堆线程(thread)同时跑同一个代码。常用框架是CUDA(NVIDIA专用,有高级功能如统一虚拟地址UVA,让CPU/GPU透明共享内存)和OpenCL(跨厂商,但功能少点)。内核以 SIMD 方式在多个标量处理器上同时调度。
性能瓶颈:
GPU 编程中最重要的性能因素之一是避免主机和设备之间的数据传输:所有数据都必须通过 PCIexpress 总线传递,这是架构的瓶颈。(访问主内存的速度大约是通过 PCIexpress 总线发送数据的两到三倍)
GPU是专用处理器,大约来说只能应对于特定任务,GPU 上的连接速度要快 2-7 倍,而由于需要数据传输,选择速度要慢 2-4 倍(He and others observed that joins are 2–7 times faster on the GPU,
whereas selections are 2–4 times slower, due to the required data transfers)
在 GDBMS 中实现良好性能的一个要点是尽可能避免数据传输。
功能决策:
我们现在讨论关系 GDBMS 与功能属性相关的设计空间。我们考虑以下设计决策:(1) 主内存与基于磁盘的系统,(2) 面向行的存储与面向列的存储,(3) 处理模型(一次元组模型与一次运算符模型),(4) 纯 GPU 与混合设备数据库,(5) GPU 缓冲区管理(逐列或按页缓冲区),(6) 混合系统的查询优化,以及 (7) 一致性和事务处理(基于锁的协议与无锁协议)。
- 主内存与基于硬盘的系统:如果必须从磁盘获取数据,GPU 加速就无法实现显著的加速,因为 IO 瓶颈主导了执行成本,因此,GPU 感知数据库架构应大量使用内存技术。
- 行存储与列存储:列存储比行存储更合适,因为列存储 (1) 允许在 GPU 上合并内存访问,(2) 实现更高的压缩率(考虑到 GPU 当前内存限制的一个重要属性),以及 (3) 减少需要传输的数据量。例如,对于列存储,只需在处理设备之间传输数据处理所需的列。
- 处理模型:一次元组方法通常应用所谓的迭代器模型,该模型应用虚函数调用通过所需的运算符传递元组。由于显卡缺乏对虚拟函数调用的支持,并且众所周知,在运行模拟它们所必需的复杂控制逻辑方面很差,因此该模型不适合 GDBMS。因此,我们认为 GDBMS 应该利用一次运算符模型。(tuple->expression?(operator at a time))
- GPU RAM vs 混合设备数据库:GDBMS 应该利用所有可用存储,而不是将自身限制在 GPU RAM 中。虽然这使数据处理变得复杂,并且需要数据放置策略,但我们仍然希望混合系统比纯 CPU 或 GPU 驻留系统更快。同时使用 CPU 和 GPU 进行处理的性能优势已经存在。
- 有效的 GPU 缓冲区管理。我们希望在更快、更小的内存空间 (GPU RAM) 中处理数据,而数据存储在更大、更慢的内存空间 (CPU RAM) 中。数据结构和数据编码通常针对处理设备的特殊属性进行高度优化,以最大限度地提高性能。另一个有趣的设计决策是应该用于管理 GPU RAM 的粒度:页面、整列还是整个表?
- 查询放置和优化。一个主要问题是自动决定应在哪个设备上执行查询的哪些部分。这个决定取决于多种因素,包括作、输入数据的大小和形状、CPU 和 GPU 的处理能力和计算特性,以及优化准则。(Selinger 风格的优化器)
- 一致性和事务处理。开发了一种无锁协议,以确保 GPU 上并行事务的冲突可序列化性。然而,据我们所知,没有一项工作明确解决 GDBMS 中的事务管理问题。因此,需要研究分布式系统已建立协议的性能特征与定制事务协议相比如何。有三种方法可以保持 CPU 和 GPU 之间的一致性:(1) 每个数据项可以严格保存在一个地方(例如,使用水平或垂直分割)。在这种情况下,我们不需要任何复制管理,并且必须解决修改后的分配问题。(2)我们可以使用已建立的复制机制,例如读一写全部或主副本。(3)系统可以始终在一次处理上执行更新
研究问题:
RQ1:在调查的系统中是否存在重复的建筑属性?
RQ2:是否有特定于应用程序的架构属性类别?
RQ3:我们能否在现有的 GPU 加速 DBMS 的基础上推断出 GPU 加速 DBMS 的参考架构?
RQ4:我们如何扩展现有的主内存 DBMS 以有效地支持 GPU 上的数据处理?
研究对象:
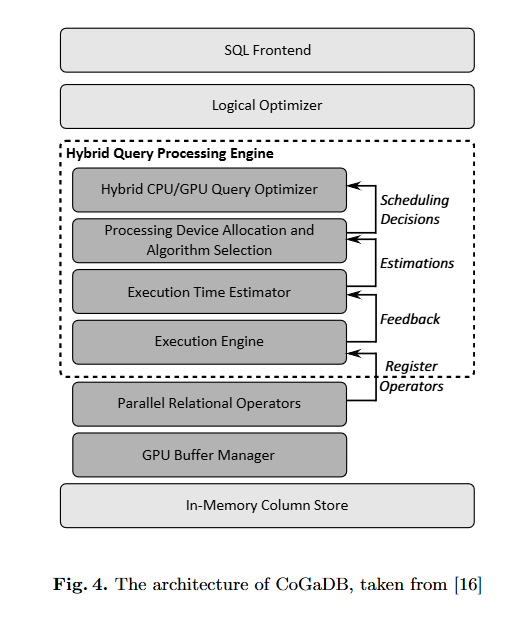
CoGaDB:
面向列的 GPU 加速 DBMS
存储系统:CoGaDB 将数据保存在磁盘上,但在启动时将整个数据库加载到主内存中。如果数据库大于主内存,CoGaDB 依靠作系统的虚拟内存管理来交换磁盘上最近使用最少的内存页面。(LRU)
存储模型:CoGaDB 将数据存储在针对内存数据库优化的数据结构中。因此,它按列存储数据,并使用字典编码压缩 VARCHAR 列。此外,数据在存储在 CPU 或 GPU 的内存中时具有相同的格式。
处理模型:CoGaDB 使用一次算子批量处理模型来有效利用内存层次结构。这是使用所有处理资源进行高效查询处理的基础。(operator-at-a-time bulk )
查询放置和优化:CoGaDB 使用**混合查询处理引擎(HyPE)**作为物理优化器。HyPE 通过跟踪所有(协)处理器(例如 CPU 或 GPU)上的负载条件来优化物理查询计划以提高设备间并行性。
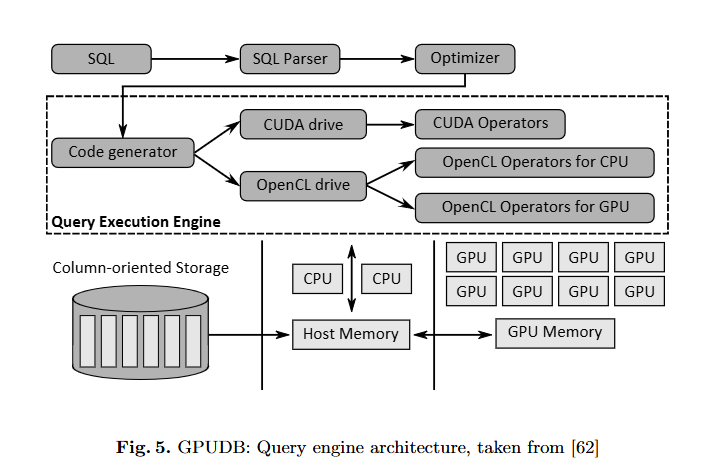
GPUDB
存储系统:GPUDB 将数据库保存在 CPU 的主内存中,以避免硬盘瓶颈。Yuan 等人发现了主内存 DBMS 在 GPU 加速执行方面的一个关键优化:如果数据存储在固定的主机内存中,查询执行时间可以显着缩短(即,Yuan 和其他人观察到 Star Schema Benchmark(SSB)的某些查询的加速速度提高了 6.5 倍)。
存储模型:GPUDB 按列存储数据,因为 GPUDB 针对仓库工作负载进行了优化。此外,GPUDB 支持常见的压缩技术(运行长度编码、位编码和字典编码),以减少 PCIe 瓶颈的影响并加速数据处理。
处理模型:GPUDB 使用面向块的处理模型:块被保存在 GPU RAM 中,直到它们被完全处理。这种处理模型也称为矢量化处理[54]。因此,通过数据传输与计算重叠,可以进一步减少 PCIe 瓶颈。对于某些查询,Yuan 和其他人观察到,与处理和数据传输没有重叠相比,速度提高了 2.5 倍。
GPUDB 将查询编译为驱动程序程序。驱动程序程序通过调用预实现的 GPU 运算符来执行查询。因此,GPUDB 在 GPU 上执行所有查询,而 CPU 仅执行调度器和后处理任务(即,在处理 SSB 查询期间,CPU 的使用时间不到 10%[62])。
查询放置和优化:GPUDB 不支持在 CPU 和 GPU 上并行执行查询。
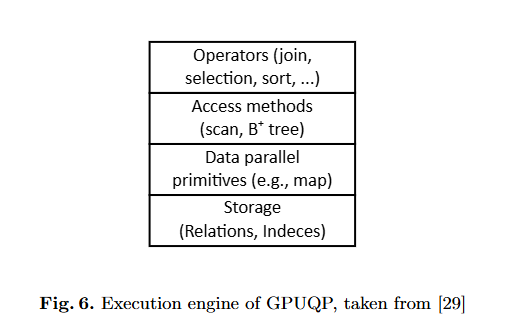
GPUQP
存储系统:GPUQP 支持内存中和基于磁盘的处理。显然,GPUQP 还尝试将数据缓存在 GPU 内存中。不幸的是,作者没有提供有关所用数据放置策略的任何详细信息。
存储模型:此外,GPUQP 利用列式存储和查询处理,这适合现代 CPU 和 GPU 的硬件功能。
处理模型:GPUQP 的基本处理策略是一次算子批量处理(operator-at-a-time bulk
processing)。但是,GPUQP 还能够为一个运算符对数据进行分区,并在 CPU 和 GPU 上同时执行该运算符。然而,对整体性能的影响很小[29]。
查询放置和优化:GPUQP 将 Selinger 式优化器与分析成本模型相结合,以选择最便宜的查询计划。对于每个运算符,GPUQP 分配 CPU、GPU 或两个处理器(分区执行)。查询优化器将查询计划拆分为多个子计划,最多包含十个运算符。对于每个子查询,将创建所有可能的计划,并选择最便宜的子计划。最后,GPUQP 将子计划组合到最终的物理查询计划中。
GPUTx
存储系统和型号:GPUTx 将所有 OLTP 数据保存在 GPU 的内存中,以最大限度地减少 PCIe 瓶颈的影响。它还应用列式数据布局以适应现代 GPU 的特性。
处理模型:处理模型不像 GPUQP 那样基于关系运算符构建。相反,GPUTx 执行预编译的存储过程,这些存储过程被分组到一个 GPU 内核中。传入事务按批量分组,这些事务是在 GPU 上并行执行的一组事务。
查询放置和优化:由于 GPUTx 在 GPU 上执行完整的数据处理,因此不需要查询放置方法。
交易:GPUTx 是我们调查中唯一支持在 GPU 上运行事务的系统,也是我们所知道的。它实现了三种基本的事务协议:两阶段锁定、基于分区的执行和基于 k 集的执行。GPUTx 的主要发现是基于锁定的协议在 GPU 上效果不佳。相反,应使用无锁协议,例如基于分区的执行或 k-set
MapD
Mostac 开发了 MapD,这是一个数据处理和可视化引擎,将 DBMS 的传统查询处理能力与先进的分析和可视化功能相结合[43]。一种应用场景是在路线图上可视化 Twitter 消息,其中推文的地理位置显示并可视化为热图。
存储系统:MapD 的数据处理组件是一个关系型 DBMS,可以处理不适合主内存的数据量。MapD 还尝试将尽可能多的数据保留在内存中以避免磁盘访问。
存储模型:MapD 以列式布局存储数据,并进一步将列划分为块。块是 MapD 内存管理器的基本单元。MapD 的基本处理模型是一次处理一个算子。由于将数据划分为块,因此也可以在块的基础上进行处理。因此,MapD 能够应用面向块的处理。
处理模型:MapD 通过将查询编译为 CPU 和 GPU 的可执行代码来处理查询。
查询放置和优化:优化器尝试将查询计划拆分为多个部分,并在最合适的处理设备上处理每个部分(例如,使用 CPU 上的索引进行文本搜索和 GPU 上的表扫描)。MapD 不假定输入数据集适合 GPU RAM,它应用流式处理机制进行数据处理。
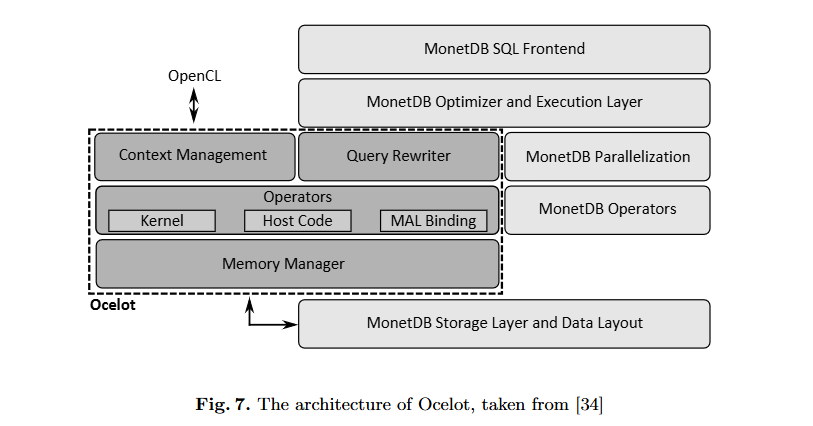
Ocelot
存储系统:Ocelot 的存储系统建立在 MonetDB 的内存模型之上。当操作员需要时,输入数据会自动从 MonetDB 传输到 GPU。为了避免昂贵的传输,运算符结果通常保存在 GPU 上。它们仅在查询结束时返回,或者当设备内存太满而无法满足请求时。此外,Ocelot 还实现了设备缓存,以在 GPU 上保持相关输入数据可用。
存储模型:Ocelot/MonetDB 将数据逐列存储在二进制关联表 (BAT) 中。每个 BAT 由两列组成:一列(可选)头部存储对象标识符,一列(必填)尾部存储实际值。
处理模型:Ocelot 继承了 MonetDB 的 operator-at-a-time 批量处理模型,但通过引入惰性求算和大量使用 OpenCL 事件模型将算子依赖信息转发到 GPU 来扩展它。这允许 OpenCL 驱动程序自动交错和重新排序作,例如,通过将传输与先前运算符的执行重叠来隐藏传输延迟。
查询放置和优化:在 MonetDB 中,每个查询计划都用 MonetDB 汇编语言(MAL)表示[35]。Ocelot 重用了这个基础设施,并添加了一个新的查询优化器,它通过用 Ocelot 的高度并行的 OpenCL MAL 指令替换普通 MonetDB 的数据处理 MAL 指令来重写 MAL 计划。
查询放置和优化:Ocelot 不支持跨设备处理,这意味着它在 CPU 或 GPU 上执行完整的工作负载。
OmniDB
存储系统和模型:OmniDB 基于 GPUQP,因此具有与 GPUQP 相似的架构属性。OmniDB 将数据保存在面向列的数据布局中的内存中。
处理模型:OmniDB 安排和处理工作单元,其粒度可能有所不同(例如,工作单元可以是查询、运算符或元组块)。尽管论文中没有明确提及 [63],但 OmniDB 也可以处理元组块这一事实有力地表明它支持面向块的处理。
查询放置和优化:关于查询放置和优化,OmniDB 为工作单元选择吞吐量最高的处理设备。为避免单个设备过载,OmniDB 的调度器确保一个处理设备上的工作负载不得超过所有处理设备上平均工作负载的一定百分比。成本模型依赖于适配器为底层处理设备提供成本函数。
Virginian
存储系统:Virginian 不使用传统的运营商缓存,而是使用统一虚拟寻址 (UVA)。这种技术允许 GPU 内核直接访问存储在固定主机内存中的数据。访问的数据通过总线透明地传输到设备,并有效地重叠计算和数据传输。
存储模型:Virgnian 实现了一种称为 tablet 的数据结构,它存储面向列的固定大小值。此外,表可以处理可变大小的数据类型,例如字符串,这些数据类型存储在平板电脑内部的专用部分中。因此,Virginian 支持 GPU 上的字符串。这是与其他 GDBMS 的主要区别,后者首先对字符串应用字典压缩,并且仅对 GPU RAM 中的压缩值起作用。
处理模型:Virginian 使用一次运算符处理作为基本的查询处理模型。它实现了一种替代处理方案。虽然大多数系统调用一系列高度并行的原语,要求每个原语调用一个新的内核,但 Virginian 使用作码模型,该模型将所有原语组合在单个内核中。这避免了将数据写回全局内存并在下一个内核中再次读取,最终导致 GPU 上的块级处理。
查询放置和优化:Virginian 可以在 CPU 或 GPU 上处理查询。因此,没有在 CPU 和 GPU 处理设备之间分配工作负载的机制,因此没有可用的混合查询优化器。
结果分析
存储系统:对于所有八个系统,可以清楚地看到它们在设计时考虑到了主内存数据库,将大部分数据库保留在 CPU 的主内存中。
存储模型:所有系统都以列式布局存储其数据,没有使用面向行的存储的系统。
处理模型:处理模型因被调查系统而异。基本上比较多是使用operator-at-a-time bulk processing

查询放置和优化:第一组在一个处理设备上执行几乎所有数据处理(单设备),第二组能够将工作负载分成几部分(CoGaDB、GPUQP、MapD、OmniDB)然后在 CPU 和 GPU上并行处理(允许跨设备)
如何在处理器间并行化和昂贵的数据传输之间进行有效权衡以实现最佳性能仍然是一个悬而未决的问题。例如:到目前为止,还没有针对具有多个 GPU 的机器的查询优化方法。
事务处理:除了 GPUTx 之外,所有接受调查的 GDBMS 都不支持事务。GPUTx 将数据严格保存在 GPU 的 RAM 中,只需将传入事务传输到 GPU,并将结果传输回 CPU。由于GPUTx 的吞吐量比同类基于 CPU 的 OLTP 引擎高 4-10 倍,因此需要在 GDBMS 中的事务处理领域进行进一步研究,以便 OLTP 系统也可以从 GPU 加速中受益。
可移植性:唯一具有可移植的、硬件无障碍数据库架构的 GDBMS 是 Ocelot 和 OmniDB。所有其他系统要么是针对供应商特定的编程框架量身定制的,要么没有技术来隐藏架构中特定于设备的运算符的详细信息。
潜在优化
GDBMS 可以实现这些优化,以充分利用混合 CPU/GPU 系统中的底层硬件:
- 高效的数据放置策略:管理 GPU RAM 有两种可能性。第一种可能性是使用缓冲区管理算法对 GPU 上的数据进行显式管理。第二种可能性是使用统一虚拟寻址 (UVA) 等机制,它使 GPU 内核能够直接访问主内存。
- GPU 感知查询优化器:GDBMS 应利用所有处理设备来最大限度地提高性能。因此,它应该将操作分担到 GPU上。GPU 感知优化器必须识别查询计划的子计划,它可以在 CPU 或 GPU 上处理这些子计划。理解上是在传统优化器上增加一层GPU优化层。
- 数据压缩:数据放置和查询优化技术试图尽可能避免数据传输。
- 数据传输和处理的同时处理:在需要执行数据传输的情况下,处理是GPU 算子的执行与数据传输作重叠。这种优化使所有硬件组件都处于忙碌状态,并且基本上将系统的性能缩小到 PCIe 总线带宽。
- 固定主机内存(pin):在必须执行复制作时加速查询处理的第三种方法是将数据保留在固定主机内存中。This optimization saves one indirection, because the DMA controller can transmit data directly to the device. 因此,GDBMS 必须决定它应该将哪些数据保存在固定的主机内存中。应该在固定的主机内存缓冲区上花费多少内存才能更快地将数据传输到 GPU 仍然是一个悬而未决的问题。
- 面向块的查询处理:GDBMS 可以通过按块而不是按运算符处理数据来避免将运算符的结果写回处理设备主内存的开销。这个想法是处理已经存储在缓存(CPU)或共享内存(GPU)中的数据,这节省了内存带宽,并显着提高了查询处理的性能。
- 基于编译的查询处理:将查询编译为可执行代码是主内存 DBMS 中的常见优化。如关系原语的 CUDA 内核组合成一个内核。这样做的优点是优化范围更大,编译器可以执行更多的优化。
- 可移植性:到目前为止,我们主要讨论性能优化。然而,所讨论的每个优化主要取决于设备。这增加了 GDBMS 的整体复杂性。对于新的处理设备类型(例如加速处理单元或英特尔至强融核),问题变得更加复杂。
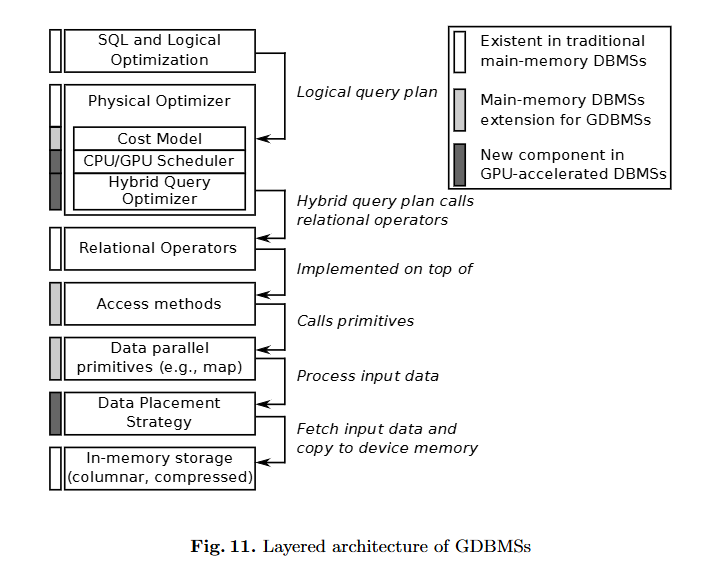
GPU 加速 DBMS 的参考架构
我们将在自上而下的视图中描述查询评估过程。在查询堆栈的上层,GPU 加速的 DBMS 实际上与“传统”DBMS 相同。它包括完整性控制、解析 SQL 查询和对查询执行逻辑优化的功能。主内存 DBMS 和 GDBMS 之间的主要区别出现在物理优化器中。虽然经典系统选择最合适的访问结构和算法来对访问结构进行作,但 GPU 加速的 DBMS 必须为处理设备上的每个算子额外决定。对于这项任务,GDBMS 需要精细化的成本模型,这些模型还可以预测 GPU 和 CPU 作的成本。根据这些估计,调度程序可以分配最便宜的处理设备。
此外,查询应使用多个处理设备来加快执行速度。因此,物理优化器必须优化 CPU/GPU 混合查询计划,这大大增加了优化空间。
关系操作在下一层实现。这些运算符通常使用访问结构来处理数据。在 GDBMS 中,必须在 GPU 上重新实现访问结构才能实现高效率。但是,根据 CPU/GPU 调度器选择的处理设备,可以使用不同的访问结构。这是查询优化器需要考虑的附加依赖项。
然后,可以将一组并行基元应用于访问结构来处理查询。在这个组件中,充分利用了 CPU 和 GPU 的大规模并行性来加速查询处理。但是,GPU 运算符只能处理存储在 GPU 内存中的数据。因此,所有访问结构都建立在数据放置组件之上,该组件根据工作负载的访问模式(例如,用于列扫描的某些列或树索引的某些节点)将数据缓存在某个处理设备上。请注意,由于数据传输对性能的主要影响,数据放置策略是 GDBMS 中性能最关键的组件。
GDBMS 的主干是典型的内存存储,它通常以面向列的格式存储数据。压缩技术不仅有利于将数据库的主要部分保留在内存中,而且压缩还可以减少 PCIe 瓶颈的影响。
未来方向
磁盘 IO 瓶颈
查询优化
一整篇看下来,其实比较深刻印象是几个点:
- GPU的并行度很高
- GPU的总线传输速率很低
- GPU的数据传输方式很麻烦
- 使用列存储
- 如何在处理器间并行化和昂贵的数据传输之间进行有效权衡以实现最佳性能仍然是一个悬而未决的问题。例如:到目前为止,还没有针对具有多个 GPU 的机器的查询优化方法。



![[论文阅读]G-OLAP](http://aplainjane.github.io/article/3356482c/wallhaven-7jpjzv_1920x1080.png)
