
[论文阅读]G-OLAP
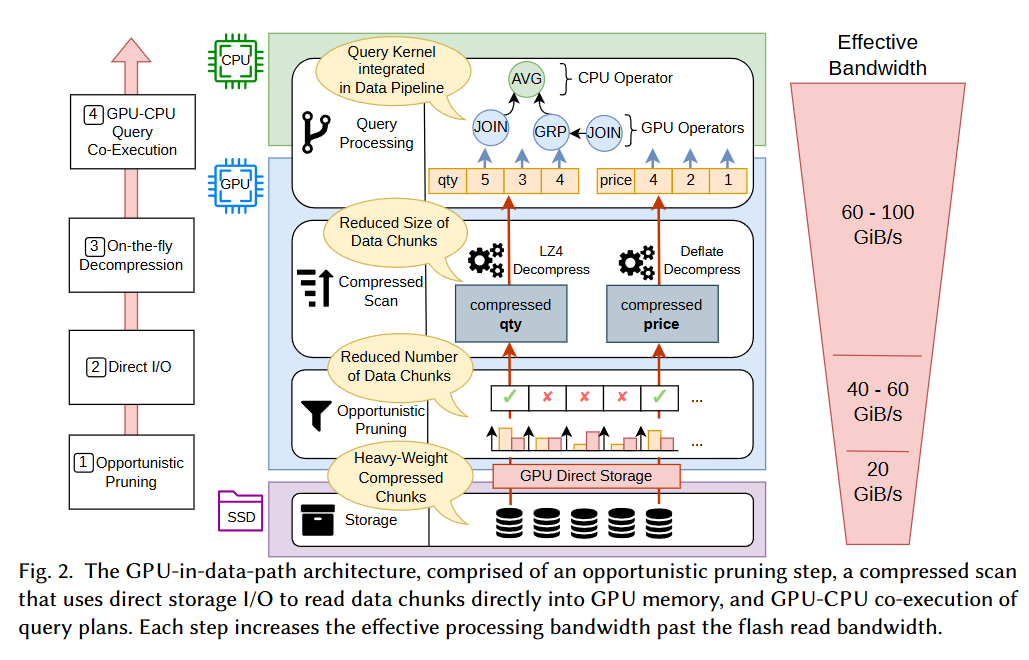
数据直接从ssd传输进gpu,不过IO依然是由cpu启动的,控制流由cpu线程处理。通过重叠 I/O与解压缩 这两种操作达到效率提升。(gpu的流操作:在实际的 I/O 大小下,SSD 需要多个并发 I/O 才能使可用 I/O 带宽饱和。使用 GDS 的一个重要方面是,并发 I/O 只能通过多个 CPU 线程发出同步(阻塞)GDS 读取或写入来实现,或者最近,通过将对异步 GDS 原语的 I/O 调用放入不同的 CUDA 流中来实现。)
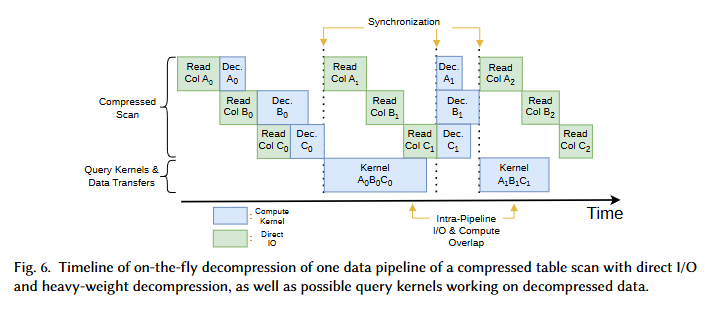
数据压缩与剪枝,修剪的操作,总体来说应该就是列存,可以绕过每次取元数据都需要取行存时无关过滤的其他列的问题。
修剪是为了充分利用gpu,还没开始数据加载前就可以针对于并行块进行修剪检查。为什么使用列存?gpu的访问形式很固定,使用列存可以更充分使用gpu的存储体结构,它更适合gpu的并行计算特性
比方一个cuda程序:
threadidx = block.dim*block.y+block.x |
肯定是使用列存来访问更方便,而且更易于变成一个通式去被并行化运行
如果是行存,那就会非常麻烦
threadidx = block.dim*block.y+block.x |
这就多了一步从表中拿出一整个记录的操作
像那种 if-col_meta 写法 列存天生塞进 warp 能一口气跑千条 行存的 if-record_meta 里头跳索引 线程间内存访问乱窜 效率崩
[^为什么会崩]: 步骤 1: memory.get(record_meta[threadidx]) 这是在全局内存中拉取第 threadidx 行的整个记录(record)。假设每行大小是 S 字节(e.g., 64 字节,包括多列)。 warp 内线程(e.g., 0-31)会访问地址:base + threadidx * S。 如果线程连续(threadidx 递增),这些地址是连续的(stride = S),但如果 S 不对齐缓存线(128 字节),或 S 太大(>128 字节),就会跨多个缓存线。结果:一个 warp 可能需要 32 次独立读取(非合并),而不是 1 次大块读取。 乱窜表现:线程 0 读 addr0 到 addr0+S-1,线程 1 读 addr0+S 到 addr0+2S-1。如果 S > 缓存粒度,地址间隙大,GPU 总线被小碎片访问淹没。实际测试中,这种 stride access 的带宽只有 coalesced 的 1/4-1/2。 步骤 2: if(record_meta[threadidx][colnum].value > 50) 这里从已拉的行中取特定列(colnum)的值。问题是: 每个线程的访问是 [threadidx][colnum],相当于 base + threadidx * S + col_offset(col_offset 是列在行内的偏移)。 这还是 stride access:线程间地址跳 S 字节。GPU 不喜欢这种“跨行跳跃”,因为它不是连续的(不像列存的紧凑数组)。 更糟的是,如果条件导致线程发散(branch divergence):一些线程 if 为 true(返回整行),其他为 false(跳过)。warp 必须执行两条路径(true 和 false),无效线程被 mask 掉,但时间还是全算。效率再崩 20-50%。 额外开销:返回 record_meta[threadidx] 又要写回或拷贝整行,放大内存流量(traffic)。GPU 带宽有限(e.g., A100 是 1.5 TB/s),多余数据会挤占有用带宽。
CPU与GPU的混合协同:
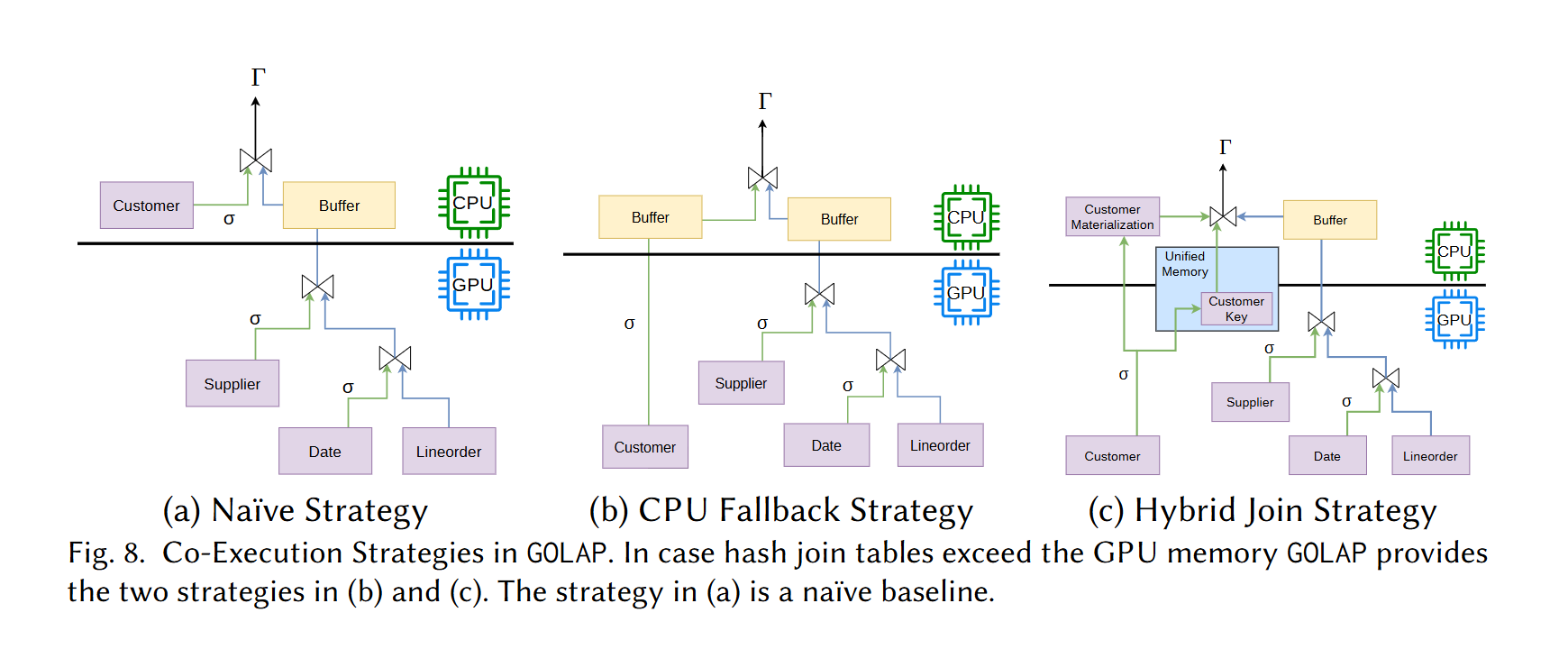
在做大表链接时,gpu完全可以使用列存的链接列先做筛选,再把超过内存的链接部分交还给cpu,只需要返回谁和谁做链接即可。





![[论文阅读]G-OLAP](http://aplainjane.github.io/article/3356482c/wallhaven-7jpjzv_1920x1080.png)
