
rmdb代码解读
引言
初赛因为太早完成了,后面有很长一段时间没有再看过代码,并且既然决赛有了线下赛的新要求,那就还是简单的就代码做一个回顾吧。
总体而言,架构与miniob也还是比较相像,架构图如下:
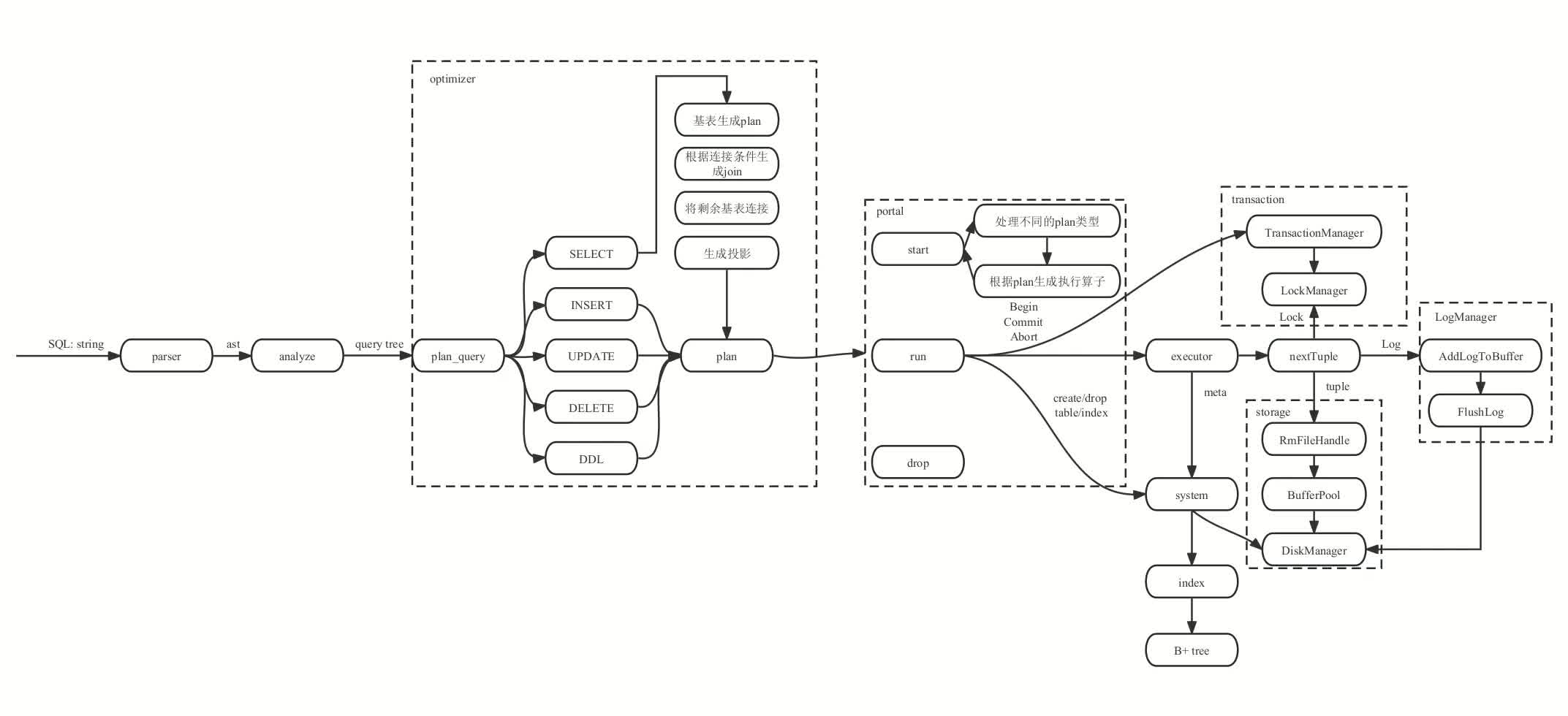
遵循的还是 语法解析->构造算子树->执行器运行算子 这个流程,题目也大多数根据这个流程进行展开,有时候会需要我们去修改到语法解析亦或是添加全新的执行器,这些都算是在已有的架构上新增功能。
参数的传递链路一般是在输入sql语句后,首先在语法解析阶段将各个col的列名与他的表关联,随后类似于where语句中的condition,join过程中的链接键,也会在这个过程中去做一个对应,比如左右值是否为表列,是否为值,随之去做好该条件的处理,储存到中间结构体Query中,后续在构造算子树的过程中取出,分配给各个算子,在这个过程中可以通过改良算子树的构造,使得执行效率得到提升,最后各个算子在run阶段就会去承担自己应该承担的责任,因为在构造算子树的过程中已经将各自的表、列、中间处理条件、链接条件分配好,那每一个算子只需要执行好自己的分内工作,将结果返回给下一个算子即可。
select语句对应的语法树结构(可以根据这个图推测一下原有语句):
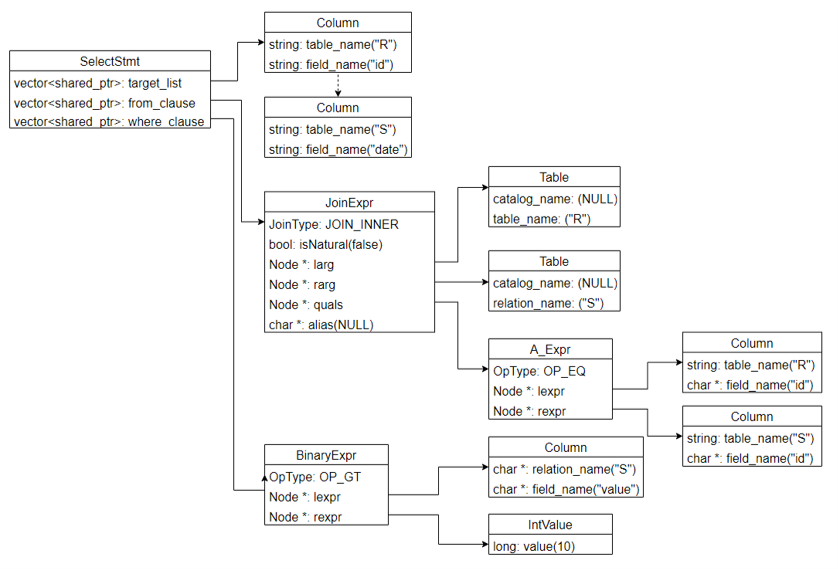
也许可能是 select id, date from R, S where R.id=S.id and S.value>10; 吧。
整体架构大概如上,然后后续的话,每一题将会就具体代码实现细节进行解析。
第一题 存储管理
本题就像万层高楼的地基,每一年基本上第一题都是如此,主要负责的正是最复杂最繁琐最不想写的底层交互,主要设计到内存、外存的各种存储管理。
但也是正因如此,第一题往往就是入门的筛选器,如果咬咬牙把这道题做下来了,那么后面的每一道题相信对你来说用心钻研都可以做出来(当然主要还是时间问题)
本题主要分为三大模块:内存、磁盘、记录
内存主要管理页面(索引页面亦或是记录页面,提供一套页面——逻辑层面体系),磁盘主要负责数据落盘(每次重新启动数据就需要从磁盘读回内存,并且提供一套实际的帧——物理层面体系),记录主要负责记录到存储元文件的对应转换(提供接口供外层结构获取记录所用)
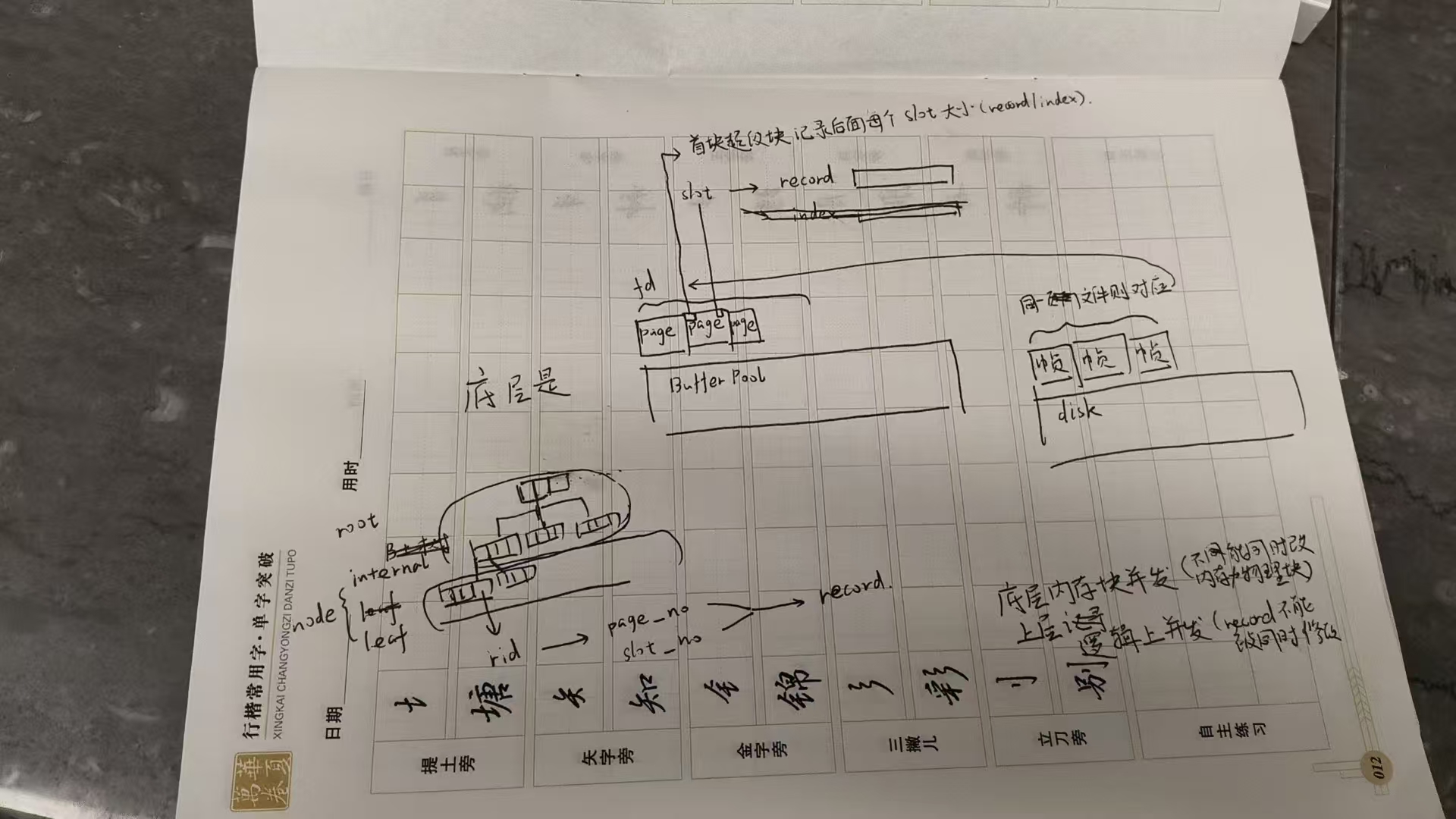
磁盘
主要比较实用的思路是:未打开或未创建的文件一般是以路径作为参数传递,打开后将对应的文件以文件句柄存入哈希中方便后续访问,已打开的文件要关闭一般是以文件句柄作为参数传递,关闭后需要清除哈希中存储的对应值。
void DiskManager::create_file(const std::string &path);
传入参数是path,需求是创建对应文件,相对来说比较容易理解,创建之后注意关闭对应文件。
void DiskManager::create_file(const std::string &path) {
// 1. 检查指定路径是否已存在文件
if (is_file(path)) {
throw FileExistsError(path);
}
// 2. 使用open系统调用创建新文件
// O_CREAT: 如果文件不存在则创建 || O_RDWR: 以读写模式打开 || 0644: 文件权限设置为rw-r--r-- (所有者读写,其他用户只读)
int fd = open(path.c_str(), O_CREAT | O_RDWR, 0644);
// 3. 检查文件创建是否成功
if (fd < 0) {
throw InternalError("Failed to create file: " + path + ", error: " + std::string(strerror(errno)));
}
close(fd);
}void DiskManager::open_file(const std::string &path);
参数path为文件名,打开对应文件,那么就需要检查对应文件是否存在,是否打开,未打开即打开并存入哈希映射。
int DiskManager::open_file(const std::string &path) {
// 1. 检查指定路径是否存在文件
if (!is_file(path)) {
throw FileNotFoundError(path);
}
// 2. 检查文件是否已经在path2fd_映射中(即是否已被打开)
if (path2fd_.count(path)) {
throw FileNotClosedError(path);
}
// 3. 尝试以读写模式打开文件
int fd = open(path.c_str(), O_RDWR);
if (fd == -1) {
perror("Error opening file");
throw InternalError("Unable to open file: " + path);
}
// 4. 将路径和文件描述符记录到映射表中
path2fd_[path] = fd;
fd2path_[fd] = path;
return fd;
}void DiskManager::close_file(int fd);
参数fd为文件句柄,依然是先检测文件是否打开,打开即关闭并且清除哈希映射。
void DiskManager::close_file(int fd) {
// 1. 从文件描述符到路径的映射中获取文件路径
std::string path = fd2path_[fd];
auto it = path2fd_.find(path);
// 2. 检查文件是否已打开(如果找不到则迭代器指向末尾)
if (it == path2fd_.end()) {
throw FileNotOpenError(fd);
}
// 3. 获取映射中存储的文件描述符
int fd__ = it->second;
if (close(fd__) == -1) {
throw InternalError("close_file: Close Error");
}
// 4. 从两个映射表中移除该文件的记录
path2fd_.erase(it);
fd2path_.erase(fd);
}void DiskManager::destroy_file(const std::string &path);
参数path为文件名,先检查是否打开,打开了还需要将页面记数置零(主要是因为索引删除、表删除需要完全清空已有页面),删除哈希,使用unlink进行删除文件。
void DiskManager::destroy_file(const std::string &path) {
// 1. 检查指定路径是否存在文件
if (!is_file(path)) {
throw FileNotFoundError(path);
}
// 2. 检查文件是否处于打开状态
if (path2fd_.count(path)) {
// 如果文件已打开,先获取其文件描述符
int fd = path2fd_[path];
// 关闭打开的文件
close(fd);
fd2pageno_[fd] = 0; // 重置页面计数
// 从路径到文件描述符的映射中移除记录
path2fd_.erase(path);
// 从文件描述符到路径的映射中移除记录
fd2path_.erase(fd);
}
// 3.尝试删除文件系统中的文件
if (unlink(path.c_str()) == -1) {
throw InternalError("Failed to unlink file: " + path + ", error: " + std::string(strerror(errno)));
}
}void DiskManager::write_page(int fd, page_id_t page_no, const char *offset, int num_bytes);
将数据写入
fd对应的文件的指定页面(page_no)中,最终数据会落到fd所代表的那个磁盘文件里,为什么不使用fsync(fd),因为过于耗时,性能堪忧。/**
* @description: 将数据写入文件的指定磁盘页面中
* @param {int} fd 磁盘文件的文件句柄
* @param {page_id_t} page_no 写入目标页面的page_id
* @param {char} *offset 要写入磁盘的数据
* @param {int} num_bytes 要写入磁盘的数据大小
*/
void DiskManager::write_page(int fd, page_id_t page_no, const char *offset, int num_bytes) {
// 1. 计算要写入的字节偏移量,基于页面编号和每页大小
off_t offset_bytes = page_no * PAGE_SIZE;
// 2. 移动文件指针到指定的偏移量
if (lseek(fd, offset_bytes, SEEK_SET) == -1) {
throw InternalError("write_page: Sad Seek Error");
}
// 3. 写入数据到文件,返回实际写入的字节数
ssize_t bytes_written = write(fd, offset, num_bytes);
if (bytes_written == -1) {
throw InternalError("write_page: Sad Write Error");
}
// 4. 检查实际写入的字节数是否与请求的一致
if (bytes_written != num_bytes) {
throw InternalError("write_page: Sad Incomplete Write");
}
}void DiskManager::read_page(int fd, page_id_t page_no, char *offset, int num_bytes);
读出对应的页面数据,主要是处理读的位置是否越界。
/**
* @description: 读取文件中指定编号的页面中的部分数据到内存中
* @param {int} fd 磁盘文件的文件句柄
* @param {page_id_t} page_no 指定的页面编号
* @param {char} *offset 读取的内容写入到offset中
* @param {int} num_bytes 读取的数据量大小
*/
void DiskManager::read_page(int fd, page_id_t page_no, char *offset, int num_bytes) {
// 1. 计算要读取的字节偏移量,基于页面编号和每页大小
off_t offset_bytes = page_no * PAGE_SIZE;
if (lseek(fd, offset_bytes, SEEK_SET) == -1) {
throw InternalError("read_page: Seek Error");
}
// 2. 获取文件大小
int file_size = get_file_size(get_file_name(fd));
off_t end_offset = offset_bytes + num_bytes;
if (end_offset > file_size) {
// 文件大小不足,扩展文件(可选)或填充剩余字节为 0
memset(offset, 0, num_bytes); // 先清零整个缓冲区
if (offset_bytes < file_size) {
// 读取文件剩余部分
ssize_t bytes_read = read(fd, offset, file_size - offset_bytes);
if (bytes_read == -1) {
throw InternalError("read_page: Read Error");
}
}
return;
}
// 3. 正常情况下,读取指定数量的数据
ssize_t bytes_read = read(fd, offset, num_bytes);
if (bytes_read == -1) {
throw InternalError("read_page: Read Error");
}
if (bytes_read < num_bytes) {
// 文件末尾,填充剩余部分为 0
memset(offset + bytes_read, 0, num_bytes - bytes_read);
}
}
内存
前置中间件:
std::mutex latch_; // 互斥锁 |
提示:在缓冲池中,需要淘汰某个脏页时,需要将脏页写入磁盘。
bool LRUReplacer::victim(frame_id_t* frame_id);
该接口的功能是选择并淘汰缓冲池中一个页面。需要在淘汰之后维护好meta_,meta_主要为了方便访问。
bool LRUReplacer::victim(frame_id_t *frame_id) {
std::scoped_lock lock{latch_};
if (LRUlist_.empty()) {
return false; // 无可淘汰页面
}
*frame_id = LRUlist_.back();
LRUlist_.pop_back();
// 标记为 NONE
auto &meta_entry = meta_[*frame_id];
meta_entry.first = PinState::NONE;
meta_entry.second = LRUlist_.end();
return true;
}void LRUReplacer::pin(frame_id_t frame_id);
pin主要就是为了固定住页面,当然就是将其从LRU链中拿出来了,为了快速访问,这就用到了上文的meta_表。使用frame_id进行快速访问。
void LRUReplacer::pin(frame_id_t frame_id) {
std::scoped_lock lock{latch_};
if (frame_id >= static_cast<frame_id_t>(meta_.size())) {
return; // 越界保护
}
auto &[state, iter] = meta_[frame_id];
if (state == PinState::UNPIN) {
// 移出LRU链
LRUlist_.erase(iter);
state = PinState::PIN;
iter = LRUlist_.end();
}
}void LRUReplacer::unpin(frame_id_t frame_id);
void LRUReplacer::unpin(frame_id_t frame_id) { |
缓冲池管理器BufferPoolManager:
前置结构体,核心与灵魂:Page与PageId,PageId主要还是要定位出页面在内存中的位置(记录fd)与页面对应的序号(page_no主要用于确定内存中的偏移)
/** |
/** |
Page *BufferPoolManager::new_page(PageId *page_id);
先从磁盘里看能不能分配出一个页的空间(逻辑上的),然后将该对应的页用一个目前被占用的页进行替换或用分配一个新的页的空间。
/**
* @description: 创建一个新的page,即从磁盘中移动一个新建的空page到缓冲池某个位置。
* @return {Page*} 返回新创建的page,若创建失败则返回nullptr
* @param {PageId*} page_id 当成功创建一个新的page时存储其page_id
*/
Page* BufferPoolManager::new_page(PageId* page_id) {
// 1. 首先,必须从磁盘分配一个页面,以确定其 page_id。
// 这至关重要,因为 page_id 决定了页面应该属于哪个分片。
page_id->page_no = disk_manager_->allocate_page(page_id->fd);
if (page_id->page_no == INVALID_PAGE_ID) {
return nullptr; // 磁盘空间不足或分配失败
}
// 2. 根据新的 page_id 计算应该在哪个分片中操作
size_t shard_idx = get_shard_index(*page_id);
auto& shard = shards_[shard_idx];
std::lock_guard<std::mutex> lock(shard->latch);
// 3. 在确定的分片中寻找一个可用的帧
frame_id_t local_frame;
if (!find_victim_page_in_shard(shard.get(), &local_frame)) {
// 如果在目标分片中找不到可用帧,理论上我们应该释放刚分配的页面
// 但为了简化,这里直接返回 nullptr。
// disk_manager_->deallocate_page(page_id->page_no); // 可选的清理步骤
return nullptr;
}
Page* page = &shard->pages[local_frame];
// 4. 更新页面元数据并将其与新的 page_id 关联
update_page_in_shard(shard.get(), page, *page_id, local_frame);
// 5. 返回新创建的页面
return page;
}Page *BufferPoolManager::fetch_page(PageId page_id);
两步走 先从page_table(各个结构体都会有自己的一个映射表方便快速访问)里找 找不到申请并替换(帧就是物理层面的描述也就是页面大小的一块内存 页面是逻辑层面的描述)
/**
* @description: 从buffer pool获取需要的页。
* 如果页表中存在page_id(说明该page在缓冲池中),则增加pin_count并返回。
* 如果页表不存在page_id(说明该page在磁盘中),则找缓冲池victim page,将其替换为磁盘中读取的page。
* @return {Page*} 若获得了需要的页则将其返回,否则返回nullptr
* @param {PageId} page_id 需要获取的页的PageId
*/
Page* BufferPoolManager::fetch_page(PageId page_id) {
// 获取对应的分片
size_t shard_idx = get_shard_index(page_id);
auto& shard = shards_[shard_idx];
std::lock_guard<std::mutex> lock(shard->latch);
// 1. 从page_table_中搜寻目标页
auto page_entry = shard->page_table.find(page_id);
// 1.1 若目标页存在于缓冲池中
if (page_entry != shard->page_table.end()) {
frame_id_t target_frame = page_entry->second;
Page* existing_page = &shard->pages[target_frame];
existing_page->pin_count_++; // 增加pin_count
shard->replacer->pin(target_frame); // 通知replacer固定该帧
return existing_page;
}
// 1.2 页面不在缓冲池中,获取一个victim frame
frame_id_t local_frame;
if (!find_victim_page_in_shard(shard.get(), &local_frame)) {
return nullptr; // 无法找到可用帧,返回nullptr
}
Page* replacement_page = &shard->pages[local_frame];
// 2. 更新页面数据并写回脏页
update_page_in_shard(shard.get(), replacement_page, page_id, local_frame);
// 3. 从磁盘读取目标页数据
disk_manager_->read_page(page_id.fd, page_id.page_no, replacement_page->data_, PAGE_SIZE);
// 4. 返回目标页(pin_count已在update_page中设置为1)
return replacement_page;
}bool BufferPoolManager::find_victim_page(frame_id_t *frame_id);
字面意思上的,依旧是两条路,判断free_list_有无空闲帧,没有就找可替换的替换掉。
/**
* @description: 从free_list或replacer中得到可淘汰帧页的 *frame_id
* @return {bool} true: 可替换帧查找成功 , false: 可替换帧查找失败
* @param {frame_id_t*} frame_id 帧页id指针,返回成功找到的可替换帧id
*/
bool BufferPoolManager::find_victim_page(BufferPoolShard* shard, frame_id_t* frame_id) {
// 1. 检查free_list_是否有可用帧
if (!shard->free_list.empty()) {
*frame_id = shard->free_list.front();
shard->free_list.pop_front();
return true;
}
// 2. 如果缓冲池已满,使用LRU replacer选择一个可淘汰的页面
if (shard->replacer->victim(frame_id)) {
return true;
}
// 如果free_list为空且replacer也没有可淘汰页面,则返回false
return false;
}void BufferPoolManager::update_page(Page *page, PageId new_page_id, frame_id_t new_frame_id);
其实就是页面更新的时候做的一系列操作,当前页面是因为是victim或者本来为空写入新页面时需要的便肯定是删除旧的页面数据,写回磁盘,并重新记录到快捷访问的表中来。
/**
* @description: 更新页面数据, 如果为脏页则需写入磁盘,再更新为新页面,更新page元数据(data, is_dirty, page_id)和page table
* @param {Page*} page 写回页指针
* @param {PageId} new_page_id 新的page_id
* @param {frame_id_t} new_frame_id 新的帧frame_id
*/
void BufferPoolManager::update_page(BufferPoolShard* shard, Page *page, PageId new_page_id, frame_id_t new_frame_id) {
// 1. 如果是脏页,写回磁盘,并将dirty标志置为false
if (page->is_dirty_) {
disk_manager_->write_page(page->id_.fd, page->id_.page_no, page->data_, PAGE_SIZE);
page->is_dirty_ = false;
}
// 2. 更新page_table:先删除旧的page_id映射,再添加新的映射
shard->page_table.erase(page->id_);
shard->page_table[new_page_id] = new_frame_id;
// 3. 重置page的data,更新page_id,并初始化数据为零
page->reset_memory(); // 清空数据
memset(page->data_, 0, PAGE_SIZE); // 初始化页面数据为零
page->id_ = new_page_id; // 更新为新的page_id
page->pin_count_ = 1; // 重置pin_count
// 4. 将该帧标记为已固定,防止被替换器再次选中
shard->replacer->pin(new_frame_id);
}bool BufferPoolManager::unpin_page(PageId page_id, bool is_dirty);
/**
* @description: 取消固定pin_count>0的在缓冲池中的page
* @return {bool} 如果目标页的pin_count<=0或不存在则返回false,否则返回true
* @param {PageId} page_id 目标page的page_id
* @param {bool} is_dirty 若目标page应该被标记为dirty则为true,否则为false
*/
bool BufferPoolManager::unpin_page(PageId page_id, bool is_dirty) {
// 获取对应的分片
size_t shard_idx = get_shard_index(page_id);
auto& shard = shards_[shard_idx];
std::lock_guard<std::mutex> lock(shard->latch);
// 1. 在page_table_中搜寻page_id对应的页面
auto page_entry = shard->page_table.find(page_id);
// 1.1 如果页面不存在,返回false
if (page_entry == shard->page_table.end()) {
return false;
}
// 1.2 页面存在,获取对应的帧ID和页面对象
frame_id_t frame_id = page_entry->second;
Page* page = &shard->pages[frame_id];
// 1.3 检查页面一致性
if (page->id_ != page_id) {
return false; // 页面ID不一致,返回false
}
// 2.1 如果pin_count_已经为0,返回false
if (page->pin_count_ <= 0) {
return false;
}
// 2.2 pin_count_大于0,自减1
page->pin_count_--;
// 2.2.1 如果自减后pin_count_变为0,通知replacer_取消固定
if (page->pin_count_ == 0) {
shard->replacer->unpin(frame_id);
}
// 3. 根据is_dirty参数更新页面的is_dirty_标志
if (is_dirty) {
page->is_dirty_ = true;
}
return true;
}bool BufferPoolManager::delete_page(PageId page_id);
类似unpin,但是多了对数据的处理,类似update_page,free_list是空闲帧列表,所以加入空闲帧后pin一下,不需要再被选中替换了,等覆盖即可。
/**
* @description: 从buffer_pool删除目标页
* @return {bool} 如果目标页不存在于buffer_pool或者成功被删除则返回true,若其存在于buffer_pool但无法删除则返回false
* @param {PageId} page_id 目标页
*/
bool BufferPoolManager::delete_page(PageId page_id) {
// 获取对应的分片
size_t shard_idx = get_shard_index(page_id);
auto& shard = shards_[shard_idx];
std::lock_guard<std::mutex> lock(shard->latch);
// 1. 在page_table_中查找目标页
auto page_entry = shard->page_table.find(page_id);
// 如果目标页不存在,返回true
if (page_entry == shard->page_table.end()) {
return true;
}
// 获取对应的帧ID和页面对象
frame_id_t frame_id = page_entry->second;
Page* page = &shard->pages[frame_id];
// 2. 如果目标页的pin_count不为0,返回false
if (page->pin_count_ != 0) {
return false;
}
// 3. 处理删除逻辑
// 3.1 如果是脏页,将数据写回磁盘
if (page->is_dirty_) {
disk_manager_->write_page(page->id_.fd, page->id_.page_no, page->data_, PAGE_SIZE);
}
// 3.2 从页表中删除目标页
shard->page_table.erase(page->id_);
// 3.3 重置页面元数据
page->is_dirty_ = false;
page->pin_count_ = 0;
page->id_ = {0, INVALID_PAGE_ID};
page->reset_memory();
// 3.4 将帧加入free_list_(使用本地frame_id)
shard->free_list.push_back(frame_id);
// 3.5 通知replacer移除该帧(如果是LRU策略,确保状态一致)
shard->replacer->pin(frame_id);
return true;
}bool BufferPoolManager::flush_page(PageId page_id);
对该页面进行获取,并且进行write_page操作。
/**
* @description: 将目标页写回磁盘,不考虑当前页面是否正在被使用
* @return {bool} 成功则返回true,否则返回false(只有page_table_中没有目标页或页面不一致时)
* @param {PageId} page_id 目标页的page_id,不能为INVALID_PAGE_ID
*/
bool BufferPoolManager::flush_page(PageId page_id) {
// 获取对应的分片
size_t shard_idx = get_shard_index(page_id);
auto& shard = shards_[shard_idx];
std::lock_guard<std::mutex> lock(shard->latch);
// 1. 在page_table_中查找目标页
auto page_entry = shard->page_table.find(page_id);
// 1.1 如果目标页不在page_table_中,返回false
if (page_entry == shard->page_table.end()) {
return false;
}
// 获取对应的帧ID和页面对象
frame_id_t frame_id = page_entry->second;
Page* page = &shard->pages[frame_id];
// 1.2 检查页面一致性
if (page->id_ != page_id) {
return false; // 页面ID不一致,返回false
}
// 2. 无论是否为脏页,都将其写回磁盘
disk_manager_->write_page(page->id_.fd, page->id_.page_no, page->data_, PAGE_SIZE);
// 3. 更新is_dirty_为false,因为写回后页面与磁盘一致
page->is_dirty_ = false;
return true;
}void BufferPoolManager::flush_all_pages(int fd);
因为是特定文件,所以是对应的句柄下的所有页面进行脏页的写回磁盘。
/**
* @description: 将buffer_pool中的所有页写回到磁盘
* @param {int} fd 文件句柄
*/
void BufferPoolManager::flush_all_pages(int fd) {
// 遍历所有分片
for (size_t shard_idx = 0; shard_idx < num_shards_; ++shard_idx) {
auto& shard = shards_[shard_idx];
std::lock_guard<std::mutex> lock(shard->latch);
// 遍历page_table_中的所有页面
for (const auto& entry : shard->page_table) {
PageId page_id = entry.first;
frame_id_t frame_id = entry.second;
// 只处理指定文件句柄fd对应的页面
if (page_id.fd == fd && page_id.page_no != INVALID_PAGE_ID) {
Page* page = &shard->pages[frame_id];
// 如果页面是脏页,写回磁盘
if (page->is_dirty_) {
disk_manager_->write_page(page->id_.fd, page->id_.page_no, page->data_, PAGE_SIZE);
page->is_dirty_ = false; // 写回后清除脏标志
}
}
}
}
}
记录
首先对于RmFileHandle,一般是一个文件句柄下的每一个页面对应一个记录文件处理器,通过位图记录页面对应槽位是否有记录,而且传参过程并不需要包含文件句柄fd,一般只需要包含对应的页面号即可。
file_hdr中的num_pages记录此⽂件分配的page个数,page_no范围为[0,file_hdr.num_pages),page_no从0开始增加,其中第0⻚存file_hdr,从第1⻚开始存放真正的记录数据。对于每⼀个数据⻚,使⽤RmPageHandle类进⾏封装管理,每⼀个数据⻚的开始部分并不直接存放记录数据,⽽是按照以下顺序进⾏存放:
| page_lsn_ | page_hdr | bitmap | slots |
|---|---|---|---|
| ⽤于故障恢复模块。 | 记录了两个信息,⼀个是num_records,记录当前数据⻚中已经分配的record个数,同时记录了next_free_page_no,记录了如果当前数据⻚写满之后,下⼀个还有空闲空间的数据⻚的page_no。 | 记录了当前数据⻚记录的分配情况。 | 则是真正的记录数据存放空间。 |
void reset_memory() { memset(data_, OFFSET_PAGE_START, PAGE_SIZE); } // 将data_的PAGE_SIZE个字节填充为0 |
但其实位图是一个比较糟糕的设计,当你在高并发环境下出现各种问题你就知道为什么会这样说了,有精力可以把位图的相关操作变成原子性操作会更好的应对高并发环境下的操作。
std::unique_ptr
RmFileHandle::get_record(const Rid &rid, Context *context) const; 通过rid获取记录,rid包含页面号,槽位号,因此可以很快的通过对应关系来获取到相应记录。bitmap用于确定该槽位是否有空。
/**
* @description: 获取当前表中记录号为rid的记录
* @param {Rid&} rid 记录号,指定记录的位置
* @param {Context*} context
* @return {unique_ptr<RmRecord>} rid对应的记录对象指针
*/
std::unique_ptr<RmRecord> RmFileHandle::get_record(const Rid& rid, Context* context) const {
// 1. 获取指定页面编号的页面句柄
RmPageHandle page_handle = fetch_page_handle(rid.page_no);
// 2. 检查页面是否存在
if (page_handle.page == nullptr) {
throw PageNotExistError("page not exist", rid.page_no);
}
// 3. 检查位图中指定槽是否被设置(即记录是否存在)
if (!Bitmap::is_set(page_handle.bitmap, rid.slot_no)) {
buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), false);
throw RecordNotFoundError(rid.page_no, rid.slot_no);
}
// 4. 获取记录所在的槽的指针
char* slot = page_handle.get_slot(rid.slot_no);
// 5. 创建并返回一个新的RmRecord对象,使用记录的大小和槽的内容
std::unique_ptr<RmRecord> record = std::make_unique<RmRecord>(file_hdr_.record_size, slot);
buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), false);
return record;
}Rid RmFileHandle::insert_record(char *buf, Context *context);
当前
fd下的每一个页面编号都有自己的一个页面句柄,先拿到页面句柄去对页面进行操作,槽位就是页面的组成单位,查看每一个槽位哪里有空,有空就插入,没空就新开一页,用新的页面句柄来进行插入记录,同时记得修改Bitmap。需要做好的维护工作:
- 页面句柄
- 文件头(下一个空闲页面)
- 位图
- 记录数量(用于表的记录数量快速获取)
- 槽位数据
/**
* @description: 在当前表中插入一条记录,不指定插入位置
* @param {char*} buf 要插入的记录的数据
* @param {Context*} context
* @return {Rid} 插入的记录的记录号(位置)
*/
Rid RmFileHandle::insert_record(char* buf, Context* context) {
// anon
// 1. 获取当前表的第一个空闲页面编号
int page_no = file_hdr_.first_free_page_no;
// 2. 根据页面编号获取页面句柄,如果没有空闲页面,则创建新页面句柄
RmPageHandle page_handle = (page_no == RM_NO_PAGE) ? create_new_page_handle() : fetch_page_handle(page_no);
// 3. 检查页面句柄是否有效
if (page_handle.page == nullptr) {
throw InternalError("Failed to fetch or create page for insertion");
}
// 4. 确保使用实际的页面编号
page_no = page_handle.page->get_page_id().page_no;
// 5. 检查页面是否已满,如果满,则创建新页面句柄
if (page_handle.page_hdr->num_records >= file_hdr_.num_records_per_page) {
page_handle = create_new_page_handle();
if (page_handle.page == nullptr) {
throw InternalError("Failed to create new page for insertion");
}
page_no = page_handle.page->get_page_id().page_no;
}
// 6. 查找空闲槽位
int slot_no = -1;
for (int i = 0; i < file_hdr_.num_records_per_page; i++) {
if (!Bitmap::is_set(page_handle.bitmap, i)) {
slot_no = i;
break;
}
}
if (slot_no == -1) {
throw InternalError("No free slot available despite page not full");
}
// // 0. 确定插入位置后申请行级排他锁 by anon
// Rid rid{page_no, slot_no};
// if (context && context->lock_mgr_) {
// context->lock_mgr_->lock_exclusive_on_record(context->txn_, rid, fd_);
// }
// 7. 获取槽位指针,并将数据复制到该槽位
char* slot_ptr = page_handle.get_slot(slot_no);
memcpy(slot_ptr, buf, file_hdr_.record_size);
Bitmap::set(page_handle.bitmap, slot_no);
page_handle.page_hdr->num_records++;
// 8. 检查页面记录是否达到最大限制,如果达到,则更新文件头
if (page_handle.page_hdr->num_records >= file_hdr_.num_records_per_page) {
file_hdr_.first_free_page_no = page_handle.page_hdr->next_free_page_no; // 更新下一个空闲页面编号
disk_manager_->write_page(fd_, RM_FILE_HDR_PAGE, reinterpret_cast<char*>(&file_hdr_), sizeof(file_hdr_)); // 写回文件头
}
buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), true); // 解锁页面,保存修改
// 更新表记录数量统计
if (sm_manager_ && !table_name_.empty()) {
sm_manager_->increment_record_count(table_name_);
}
return Rid{page_no, slot_no};
}void RmFileHandle::insert_record(const Rid &rid, char *buf);
相较之下,少了空闲槽位的查找,因为是用于恢复的,因此会有已有的slot_no和page_no存储在rid结构内,不需要手动分配。
/**
* @description: 在当前表中的指定位置插入一条记录
* @param {Rid&} rid 要插入记录的位置
* @param {char*} buf 要插入记录的数据
*/
void RmFileHandle::insert_record(const Rid& rid, char* buf) {
// anon
// 0. 不申请行级排他锁 by anon
// no context, why? so no lock?
// if (context && context->lock_mgr_) {
// context->lock_mgr_->lock_exclusive_on_record(context->txn_, rid, fd_);
// }
// 1. 获取指定页面编号的页面句柄
RmPageHandle page_handle = fetch_page_handle(rid.page_no);
// 2. 检查指定槽位是否已被占用
if (Bitmap::is_set(page_handle.bitmap, rid.slot_no)) {
buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), false);
return;
}
// 3. 获取槽位指针,并将数据复制到该槽位
char* slot_ptr = page_handle.get_slot(rid.slot_no);
memcpy(slot_ptr, buf, file_hdr_.record_size);
// 4. 更新位图,标记该槽位为已使用
Bitmap::set(page_handle.bitmap, rid.slot_no);
page_handle.page_hdr->num_records++;
// 5. 检查页面记录是否达到最大限制,并且是否在第一个空闲页面中
if (page_handle.page_hdr->num_records >= file_hdr_.num_records_per_page &&
rid.page_no == file_hdr_.first_free_page_no) {
file_hdr_.first_free_page_no = page_handle.page_hdr->next_free_page_no; // 更新文件头中的第一个空闲页面编号
disk_manager_->write_page(fd_, RM_FILE_HDR_PAGE, reinterpret_cast<char*>(&file_hdr_), sizeof(file_hdr_)); // 写回文件头到磁盘
}
buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), true);
// 更新表记录数量统计
if (sm_manager_ && !table_name_.empty()) {
sm_manager_->increment_record_count(table_name_);
}
}void RmFileHandle::delete_record(const Rid &rid, Context *context);
处理步骤为:修改位图,修改后若页面数据满了,进行页面的写磁盘,并释放页面句柄。
/**
* @description: 删除记录文件中记录号为rid的记录
* @param {Rid&} rid 要删除的记录的记录号(位置)
* @param {Context*} context
*/
void RmFileHandle::delete_record(const Rid& rid, Context* context) {
// anon
// 0. 不申请行级排他锁,让sql scan来做 by anon
// if (context && context->lock_mgr_) {
// context->lock_mgr_->lock_exclusive_on_record(context->txn_, rid, fd_);
// }
// 1. 获取指定页面编号的页面句柄
RmPageHandle page_handle = fetch_page_handle(rid.page_no);
// 2. 检查指定槽位是否已被使用
if (!Bitmap::is_set(page_handle.bitmap, rid.slot_no)) {
buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), false);
return;
}
// 3. 重置位图,标记该槽位为未使用
Bitmap::reset(page_handle.bitmap, rid.slot_no);
page_handle.page_hdr->num_records--; // 减少当前页面的记录计数
// 4. 如果当前页面的记录数减少到最大记录数减一,释放页面句柄
if (page_handle.page_hdr->num_records == file_hdr_.num_records_per_page - 1) {
release_page_handle(page_handle); // 释放页面句柄
}
buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), true);
// 更新表记录数量统计
if (sm_manager_ && !table_name_.empty()) {
sm_manager_->decrement_record_count(table_name_);
}
}void RmFileHandle::update_record(const Rid &rid, char *buf, Context *context);
找槽位,换数据,解决。
/**
* @description: 更新记录文件中记录号为rid的记录
* @param {Rid&} rid 要更新的记录的记录号(位置)
* @param {char*} buf 新记录的数据
* @param {Context*} context
*/
void RmFileHandle::update_record(const Rid& rid, char* buf, Context* context) {
// anon
// 0. 不申请行级排他锁,让sql scan来做 by anon
// if (context && context->lock_mgr_) {
// context->lock_mgr_->lock_exclusive_on_record(context->txn_, rid, fd_);
// }
// 1. 获取指定页面编号的页面句柄
RmPageHandle page_handle = fetch_page_handle(rid.page_no);
// 2. 检查指定槽位是否已被使用s
if (!Bitmap::is_set(page_handle.bitmap, rid.slot_no)) {
throw std::runtime_error("Record does not exist at RID: " +
std::to_string(rid.page_no) + "," + std::to_string(rid.slot_no));
}
// 3. 获取槽位指针,并将新数据复制到该槽位
char* slot_ptr = page_handle.get_slot(rid.slot_no);
memcpy(slot_ptr, buf, file_hdr_.record_size);
// 4. 解锁页面,保存修改
buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), true);
}
对于RmScan类,参赛队伍需要实现的接口如下:
RmScan(const RmFileHandle *file_handle);
用于扫描,有记录与无记录使用不同初始化方式。
/**
* @brief 初始化file_handle和rid
* @param file_handle
*/
RmScan::RmScan(const RmFileHandle *file_handle) : file_handle_(file_handle) {
// 1. 初始化为无效位置
rid_.page_no = RM_NO_PAGE;
rid_.slot_no = -1;
// 2. 检查是否有记录页面
if (file_handle_->file_hdr_.num_pages > RM_FIRST_RECORD_PAGE) {
rid_.page_no = RM_FIRST_RECORD_PAGE;
rid_.slot_no = -1;
next(); // 定位到第一个有效记录
}
}void RmScan::next() override;
记录扫描,每次调用next就会返回下一条逻辑数据的地址。
移动游标
- 将内部游标(rid_)移动到下一条有效记录的位置,跳过无效槽位(如已删除的记录或空槽位)。
惰性加载
- 仅在调用 next() 时才会加载下一页或下一个槽位,减少内存占用(适合大表遍历)。
封装遍历逻辑
- 隐藏底层存储细节(如页面管理、位图检查),对外提供简单的迭代接口。
/**
* @brief 找到文件中下一个存放了记录的位置
*/
void RmScan::next() {
// 1. 如果当前记录的页面编号为RM_NO_PAGE,表示已经到达末尾
if (rid_.page_no == RM_NO_PAGE) {
return; // 已到达末尾
}
int total_pages = file_handle_->file_hdr_.num_pages; // 获取文件中的总页面数
int max_slots = file_handle_->file_hdr_.num_records_per_page; // 获取每页的最大记录槽位数
// 2. 遍历页面,直到找到下一个记录
while (rid_.page_no < total_pages) {
// 获取当前页面的句柄
RmPageHandle page_handle = file_handle_->fetch_page_handle(rid_.page_no);
int slot = rid_.slot_no + 1; // 从下一个槽位开始检查
// 遍历当前页面的所有槽位
while (slot < max_slots) {
if (Bitmap::is_set(page_handle.bitmap, slot)) {
rid_.slot_no = slot; // 找到记录,更新槽位编号
file_handle_->buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), false);
return;
}
slot++; // 检查下一个槽位
}
// 如果当前页面没有更多记录,解锁页面并移动到下一个页面
file_handle_->buffer_pool_manager_->unpin_page(page_handle.page->get_page_id(), false);
rid_.page_no++; // 转到下一个页面
rid_.slot_no = -1; // 重置槽位编号
}
// 3. 如果遍历完所有页面仍未找到记录,设置页面编号为RM_NO_PAGE,表示到达末尾
rid_.page_no = RM_NO_PAGE; // 到达末尾
}bool RmScan::is_end() const override;
文件末尾即地址无效。
/**
* @brief 判断是否到达文件末尾
*/
bool RmScan::is_end() const {
// anon
return rid_.page_no == RM_NO_PAGE;
}
第二题 查询执行
1、元数据管理与DDL语句
本任务要求参赛队伍对数据库的元数据进行管理,并实现基本的DDL语句,包括create table和drop table两种语句。大赛提供的框架中,与元数据管理和DDL语句相关的代码文件位于src/system文件夹下,代码框架中提供了create table语句的实现方式。
2、DQL语句和DML语句
DML语句要求实现基本的增删改,即insert、delete、update语句。DQL语句要求实现select语句。在完成本任务之前,参赛队伍需要首先阅读项目结构文档中查询解析、查询优化、查询执行的相关说明,以及代码框架中src/analyze、src/optimizer、src/execution文件夹下的代码文件,参赛队伍需要实现代码框架中未提供的功能,包括语义检查、查询执行计划的生成、执行算子等。
在开始之前,其实可以提前查看下execution_manager.cpp,可以更好的对整个执行器的运行逻辑有更清晰的了解。
重点在于beginTuple()、is_end()、nextTuple()、Next()这些函数。
// 执行query_plan |
create_table语句
算子构造阶段解析为DDL语句 随后调用sm_manager_的create_table语句进行执行
create_table主要是创建表的元信息并进行落盘操作
创建一个表元 并将col的定义信息都添加到这个表元中的列信息中,并创建对应文件且打开,最后通过落盘实现持久化。
其实本质上还是一套流程:语法解析->构造算子->执行算子->先对内存处理->落盘更新
drop_table语句
那我们就反过来即可
检查内存中是否存在 存在即先获取表元 接着根据表元删除记录、索引(外存),最后清除表元文件即可(内存)。最后也需要落盘。
一般数据清理都是先外存 后内存。
1、记录
// 4. 关闭并删除表的记录文件 |
2、索引
// 5. 关闭并删除表相关的索引文件 |
3、内存
// 6. 从数据库元数据中移除表 |
insert、delete、update语句
没记错的话insert语句应该也是实现好了的。
查看insert语句其实应该更能看出添加一个新的sql语句所需要修改的所有文件。
对照着一个个流程来,那就是:语法解析->构造算子->执行算子
语法解析阶段:
主要修改:
lex.l:添加sql语句的识别词汇
yacc.y:添加sql语句的整句处理逻辑
ast.h:添加结构体定义用于存储处理后结果
analyze.h:添加query结构体中需要的中间变量用于传递给算子
analyze.cpp:处理语法解析后的结果(提取ast.h中的各种变量使之与实际存在的表、列产生映射)加入query结构体中传递给算子构造阶段
构造算子阶段:
planner.cpp:提取analyze传递过来的query结构体中的参数和变量,赋予plan,将stmt转为plan。在构造完planner后,将planner的参数赋予executor,这样各个executor就拥有了从parser阶段传过来的参数
optimizer.h:其实把优化算子构造的地方写在这里会好一点,但是在写第四题的时候贪图方便,优化器很多内容都是写在planner里面的,算是一个比较大的代码缺憾
执行器阶段:
executor_insert.h:当前算子执行的操作,为了统一接口,每个执行器都提供类似迭代器的接口:初始化(begin)、获取下一个(next)、返回当前(Next)、检查结束(is_end)。这样,上层执行器可以像遍历一个集合一样,逐个拉取(pull)下层的结果,而不需要一次性加载所有数据。
beginTuple():初始化扫描,找到第一个匹配记录
nextTuple():移动到下一个匹配记录
上面两种一般只会在需要扫描记录的执行器中出现,insert只持有Next(),因为只需要单条记录的操作。
- Next():一般是会用于获取当前算子的记录或执行当前算子的操作。
不同算子如何交互?像ProjectionExecutor,一般在构造阶段会比较晚构造,这是为了能够在构造他的时候传入前一个算子的指针,这样的话就可以通过调用prev来获取到前一个算子的Next()。
可以理解为beginTuple和nextTuple是迭代器,Next就是获取当前迭代器对应位置下的记录。
查看execution_manager.cpp,可以发现,一般dml语句只会调用到Next()函数:
// 执行DML语句 |
所以基本上update,insert,delete只需要修改Next函数即可。
这三个语句在实现上基本上都是差不多,遵循修改记录层、修改索引层这两层关系。
提供一个最基础的insert执行器实现:
/* Copyright (c) 2023 Renmin University of China |
因为在底层上是一个**rid(page_no,slot_no)**映射一条record,而record又是不会分col进行存储,所以一般来说,record是将所有要插入的数据拼接然后插入到某个位置,等待后续取出时再根据列元信息进行拆分得到每个col的对应值。
auto Tuple = executorTreeRoot->Next(); |
因此插入阶段只需全部数据字段糅合在一起插入即可。
update、delete实现基本类似,update本质上可以理解为用新record的所有内容覆盖老record的内容,只不过需要考虑到索引的更新问题,而且更新时是否会碰到唯一性,delete就是直接将record是否存在的判断置为否即可,内存处理可以让该对应位置的数据允许被覆盖,也可以真正去做一个删除。
区别于insert,后两者的实现都依赖于记录存在,也就是说,都是针对于rid进行处理,因此可以直接利用rid去获取记录与针对rid做删除修改,相对来说会更加方便。
/** |
第三题 唯一索引
索引内容有点多 想先咕咕了
大概提一下今年碰到的一些问题吧
初赛的索引很快就过去了,但是决赛的大批量数据时非常容易出现很多问题
像是一开始我们的索引b+树缺少内部节点
补全后出现了内部节点分裂逻辑有问题
还有就是跳页逻辑有问题
都是比较常见的错误
后续有时间再针对索引做一个详细补充和回顾
其实今年有比较多队伍都放弃b+树索引了,转而使用其他索引类型
像是hnsw这类聚簇索引(oceanbase大赛中使用到的)
据说性能提升会比较大
分界线
上面三道题算是这个比赛的基础原件了,写完之后后面的题目都是相对来说会好写一点,也有一些是凭借现有代码理解可以攻克的难关。
而且也比较多变,同时我也比较懒(这个是主要原因吧喂),所以就大致总结一下吧。
第四题 查询优化
这道题相对而言有两个难点
一个是explain语句
一个是输出格式
explain我们的想法是通过走完一遍正常的plan之后,挨个遍历所有的算子,打印出来算子树,效果还算不错
输出格式方面,主要还是一些缩进和condition中条件排序比较棘手,最后是join的时候,确保小表连大表
第五题 聚合函数与分组统计
由于这道题不是我做的,后续也没有去仔细阅读,其实理解也不是特别深刻,不过可以贴一下一位队员的笔记:
聚合函数:
select count(a) from t;
语法解析:
先过lex.l识别COUNT等,yacc.y中dml->selector->expressionList->expr->aggr_expr->COUNT ‘(‘ col ‘)’构造聚合表达式。传入agg_name和col,同时也传入groupby和having
analyze:
1. 进入SelectStmt的if中,判断是否为聚合表达式,创建agg_call,传入聚合名和别名,判断是否为count(*):*
1. *若是:则调用get_all_cols,获取所有列名,并获取第一列名替换count(*),构造第一列的col去加入agg_call.args。
2. 若不是:则直接把aggr->args的东西传给agg_call.args。
2. 最后query->agg_calls.push_back(agg_call);
3. 然后对query->agg_calls的args进行表名验证,并调用check_column_with_type去获取agg的返回值类型,具体是
1. 如果是count(*),则table_name为空,col_name 为第一列,返回第一列的类型,如果不是,则返回table_name和col_name相同列的类型。
2. 若有groupby,则将groupby的列加入cols2并验证表是否存在。
3. 若有having,先调用getclause2,若是count(*),则将所有列加入cond.agg_call.args,若不是则加入对应列,然后使用convert_sv_value处理传递右值。
optimize:
do_planner->generate_select_plan,在此构造AggregatePlan,构造后顺序为aggregateplan->seqscan.然后构造投影plan,放到agg上层
最后构造selectplan放在最上层。
portal->start:
递归将plan转换为executor。
portal->run:
- 主要是调用到aggregate的executor.
- 首先在构造函数中构造好输出列,即output_cols_,包含普通列和聚合列,然后将having中的聚合函数也加入到agg_calls中,
- begintuple()中:先调用seq_scan算子获取记录,并根据记录值进行分组,如”1#”,若无group,则全部加入default组,处理空表特殊情况,调用fetch_next_valid_group()获取第一组的聚合函数值,具体为先找到符合having的组(调用satisfies_having确认,satisfies_having中先计算聚合函数值,后续与正常的where判断一致),然后compute_aggregates(获取data值,然后根据不同聚合函数名取计算)计算聚合函数值返回。
- nexttuple():把group的组值++,然后调用fetch_next_valid_group()
- is_end():组值大于group的size。
第六题 半连接
算是比较简单的一道题,可能唯一的坑点在于,已经选出来的记录/列值,不可以出现第二次。
第七题 基础事务语句
大体框架已经是写好了,只需要顺着逻辑去看代码即可。
第八题 MVCC
贴一下详细学习过程:mvcc初步学习
第九题 故障恢复






