
claude-code代码阅读
运行架构

使用标准的ReAct循环,不断追加工具结果。
工具调用使用MCP协议
- 每个工具有一个处理函数。路径沙箱防止逃逸工作区。
- dispatch map 将工具名映射到处理函数。
- 循环中按名称查找处理函数。循环体本身与 s01 完全一致。
- 加工具 = 加 handler + 加 schema。循环永远不变。
- tool schema 是给模型看的说明
- handler map 是代码里的分发入口
tool_result是结果回流到主循环的统一出口
任务进行时会写出一个待办清单,并且查看和修改清单也会作为工具

{
"content": "Read the failing test",
"status": "pending" | "in_progress" | "completed",
"activeForm": "Reading the failing test",
}任务锁,任务会有严格的依赖关系,必须前几个任务完成后才可以后续任务进行
任务也需要落盘,写成文件,方便恢复与后续步骤或代理获取相关上下文
**todo 更像本轮计划,task 更像长期工作板。**简单任务无需任务拆解,复杂任务拆解后分离成独立task

后台任务的产生。
子代理与上下文隔离
- 当前正在和用户对话、持有主
messages的 agent,就是父智能体。 - 父智能体临时派生出来,专门处理某个子任务的 agent,就是子智能体。
- 父智能体有自己的
messages - 子智能体也有自己的
messages - 子智能体的中间过程不会自动写回父智能体
子智能体的价值,不是“多一个模型实例”本身,而是“多一个干净上下文”。
- 子智能体从父智能体获取任务
- 子智能体使用自己的消息列表
- 子智能体只拿必要工具(不允许派生新的子智能体)
- 只把结果带回父智能体
特殊情况:前面的最小实现是:
- 子智能体从空白上下文开始
这叫最朴素的子智能体。
但有时一个子任务必须知道父智能体之前在聊什么。
例如:
“基于我们刚才已经讨论出来的方案,去补测试。”
这时可以用
fork:- 不是从空白
messages开始 - 而是先复制父智能体的已有上下文,再追加子任务 prompt
- 当前正在和用户对话、持有主
skill系统
- 作为渐进式的知识不主动加载
- 提供工具给内部agent进行load
- skill包含知识文档、该skill的仓库代码、代码的使用说明
权限系统,可以直接提供一份过滤清单,一些被严格阻止的命令触发时即不给运行
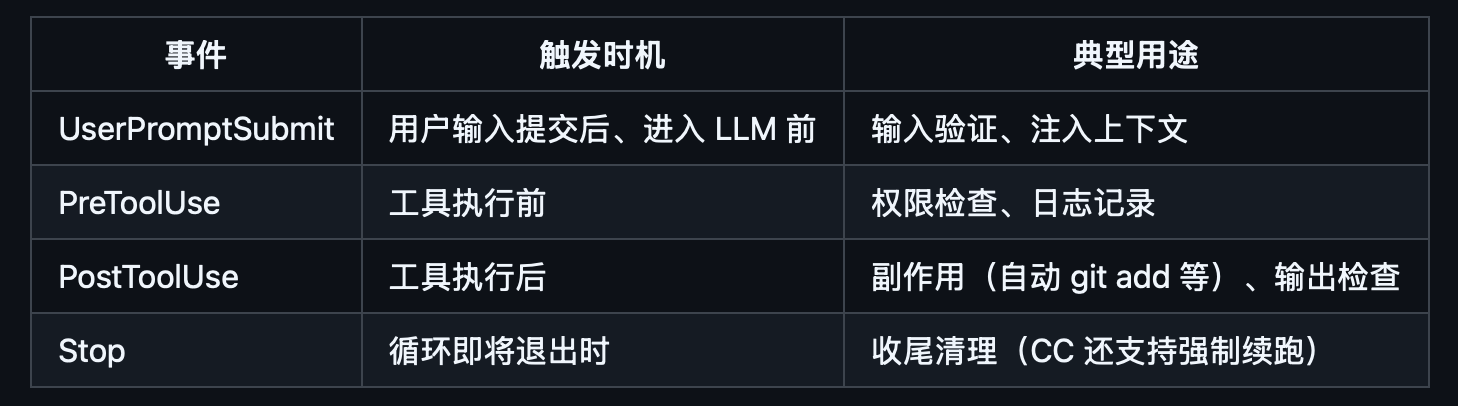
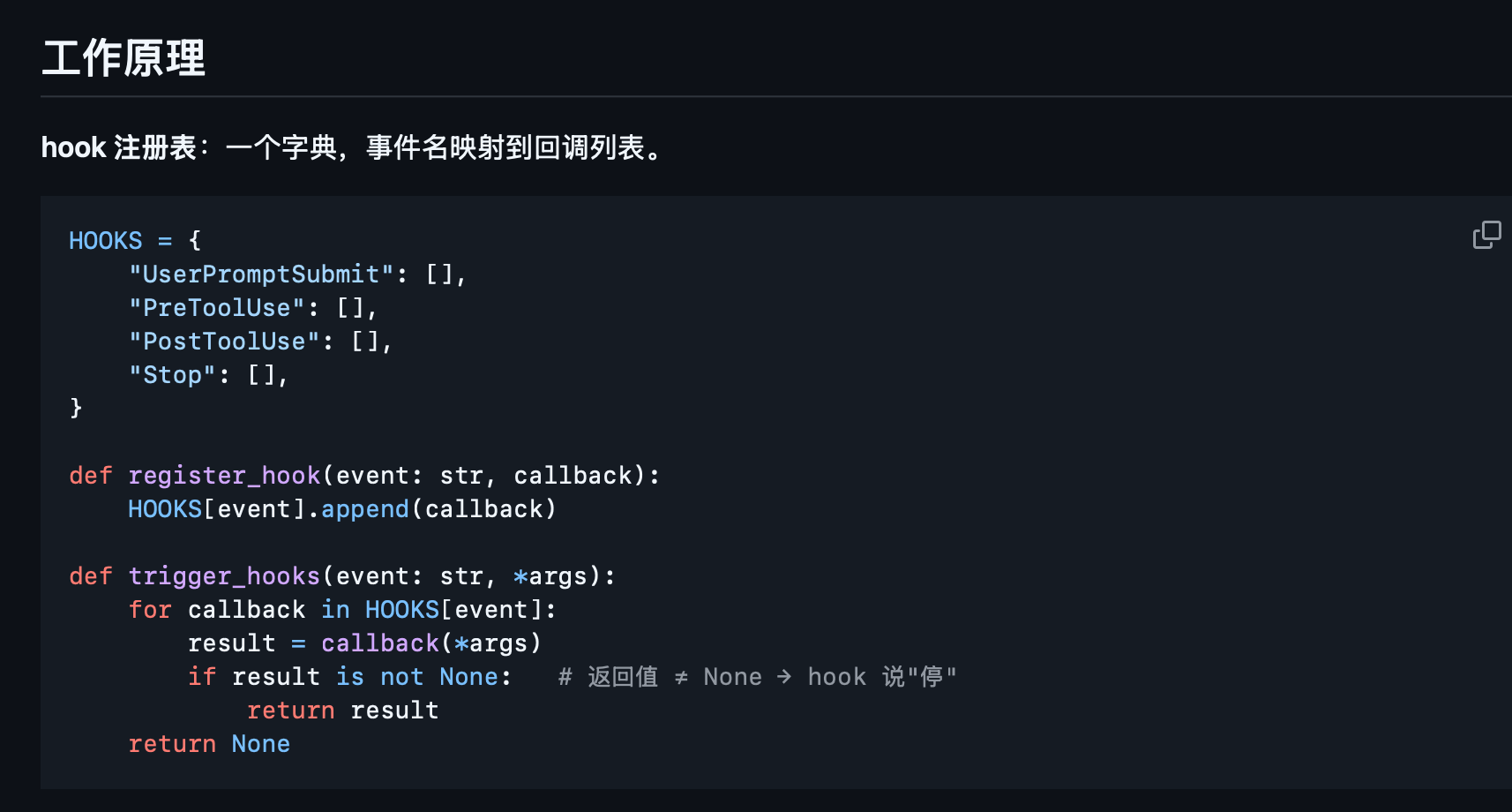
hook,主循环之外的拓展,类似于trigger,当主循环触发到某些关键任务时,会主动派发给hook的接收端,获取到上下文/目标,最后返回给主循环。理解为可拓展的模块
/btw这种并行实现会将tool_result与异步的tool_notification做一个统一然后回复
定时任务:调度器做的是“记住未来”,不是“取代主循环”。
- 时间到了
- 先发通知
- 再让主循环决定怎么处理
这样系统行为更透明,读者也更容易理解。
但是在我的理解里,调度器可以作为一个消息管道的发布者,自带定时器,在条件触发时再发布委托给监听的agent工作。
上下文管理/记忆
必须要有层级管理来控制上下文膨胀

层级管理:

工具输出过长时,保留预览,并且完整结果落盘,可以使得上下文膨胀减缓
过于久远的工具输出做压缩,并且保留一些较为关键的摘要
保留主动压缩的工具调用,用户要求时即可触发,方便管理上下文
不要存进memory的内容:
不要存的东西 为什么 文件结构、函数签名、目录布局 这些可以重新读代码得到 当前任务进度 这属于 task / plan,不属于 memory 临时分支名、当前 PR 号 很快会过时 修 bug 的具体代码细节 代码和提交记录才是准确信息 密钥、密码、凭证 安全风险 最小心智模型:
conversation
|
| 用户提到一个长期重要信息
v
save_memory
|
v
.memory/
├── MEMORY.md # 索引
├── prefer_tabs.md
├── feedback_tests.md
└── incident_board.md
|
v
下次新会话开始时重新加载- 单条 memory 文件
最简单也最清晰的做法,是每条 memory 一个文件。
---
name: prefer_tabs
description: User prefers tabs for indentation
type: user
---
The user explicitly prefers tabs over spaces when editing source files.- 索引文件
MEMORY.md
最小实现里,再加一个索引文件就够了:
# Memory Index
- prefer_tabs: User prefers tabs for indentation [user]
- avoid_mock_heavy_tests: User dislikes mock-heavy tests [feedback]索引的作用不是重复保存全部内容。
它只是帮系统快速知道“有哪些 memory 可用”。
最小实现步骤
第一步:定义 memory 类型
MEMORY_TYPES = ("user", "feedback", "project", "reference") |
第二步:写一个 save_memory 工具
最小参数就四个:
namedescriptiontypecontent
第三步:每条 memory 独立落盘
def save_memory(name, description, mem_type, content): |
第四步:会话开始时重新加载
把 memory 文件重新读出来,拼成一段 memory section。
第五步:把 memory section 接进系统输入
这一步会在 s10 的 prompt 组装里系统化。
最小心智模型
最容易理解的方式,是把 system prompt 想成 6 段:
1. 核心身份和行为说明 |
然后按顺序拼起来:
core |
故障恢复
- 输出被截断
模型还没说完,但 token 用完了 - 上下文太长
请求装不进模型窗口了 - 临时连接失败
网络、超时、限流、服务抖动
LLM call |
- 中间态的保存,为了使停电等中断的恢复。(很多都可以落盘组织)
- 在agent本身的task调度之外,需要考虑到故障恢复,将任务及时落盘,然后后续如果遇到中断可以唤醒起新agent认领任务重新执行
多agent架构
这里是完全区分于subagent的之外的独立的各个主循环中的agent的通信。
这一章最简单的理解方式,是把每个队友都想成:
一个有自己循环、自己收件箱、自己上下文的人。
lead
|
+-- spawn alice (coder)
+-- spawn bob (tester)
|
+-- send message --> alice inbox
+-- send message --> bob inbox
alice
|
+-- 自己的 messages
+-- 自己的 inbox
+-- 自己的 agent loop
bob
|
+-- 自己的 messages
+-- 自己的 inbox
+-- 自己的 agent loop各个member间通过邮箱进行交流:
第一步:先有一份队伍名册
class TeammateManager:
def __init__(self, team_dir: Path):
self.team_dir = team_dir
self.config_path = team_dir / "config.json"
self.config = self._load_config()名册是本章的起点。
没有名册,就没有真正的“团队实体”。第二步:spawn 一个持久队友
def spawn(self, name: str, role: str, prompt: str):
member = {"name": name, "role": role, "status": "working"}
self.config["members"].append(member)
self._save_config()
thread = threading.Thread(
target=self._teammate_loop,
args=(name, role, prompt),
daemon=True,
)
thread.start()这里的关键不在于线程本身,而在于:
队友一旦被创建,就不只是一次性工具调用,而是一个有持续生命周期的成员。
第三步:给每个队友一个邮箱
教学版最简单的做法可以直接用 JSONL 文件:
.team/inbox/alice.jsonl
.team/inbox/bob.jsonl发消息时追加一行:
def send(self, sender: str, to: str, content: str):
with open(f"{to}.jsonl", "a") as f:
f.write(json.dumps({
"type": "message",
"from": sender,
"content": content,
"timestamp": time.time(),
}) + "\n")收消息时:
- 读出全部
- 解析为消息列表
- 清空收件箱
第四步:队友每轮先看邮箱,再继续工作
def teammate_loop(name: str, role: str, prompt: str):
messages = [{"role": "user", "content": prompt}]
while True:
inbox = bus.read_inbox(name)
for item in inbox:
messages.append({"role": "user", "content": json.dumps(item)})
response = client.messages.create(...)
...这一步一定要讲透。
因为它说明:
队友不是靠“被重新创建”来获得新任务,而是靠“下一轮先检查邮箱”来接收新工作。
定义各个消息类型:
- 协议 1:优雅关机
- 协议 2:计划审批
- 协议 3:交接
- 协议 4:签收
- 普通消息
自主代理:
- 主代理可以发布一个event(包含委托条件)
- (符合条件的)空闲代理可以认领event自己进行干活
- 因此代理也就需要了自我状态的标签
worktree的设计:每个代理都有自己的一个git版本。
- 方便主代理进行审阅和接受、拒绝
- 隔离各个代理工作环境
MCP 中间插件:

层级 它是什么 它负责什么 plugin manifest 一份配置声明 告诉系统要发现和启动哪些 server MCP server 一个外部进程 / 连接对象 对外暴露一组能力 MCP tool server 暴露的一项具体调用能力 真正被模型点名调用






