
mvcc的初步学习
前言

这几天正在打rmdb这个比赛,初赛还在进行中,虽然在开赛第一周的时候就已经基本上完成了所有题目了,但是还是有些比较困难的知识点没搞懂,而且像mvcc这种题目,非常玄乎,队友把他搞出来了,但自己却是一知半解,刚好15445-2024fall有这个的专门讲解,那就稍微看看做下笔记,以及后续再跟着代码再看一遍……
成绩镇帖(2025-5-26 16:12):
初步概念学习
先感慨一句,这玩意做成分布式的不炸了吗……
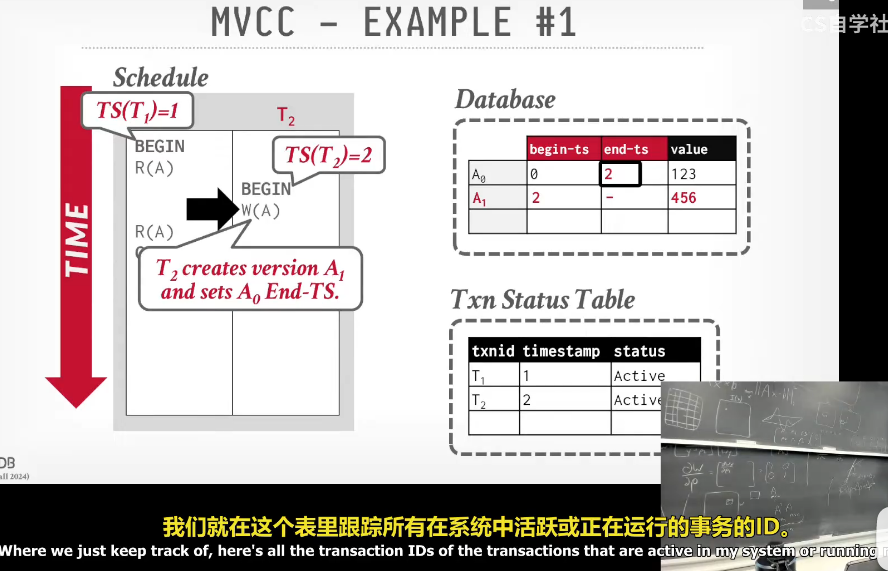
线性流程大概如下:
- 事务t1和t2分别begin 并且同时修改一个元组A
- t1先修改为A1
- 修改的时候分配一个开始时间戳给A1
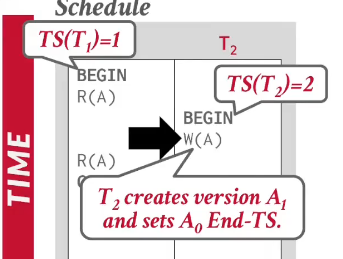
- 他们的结束时间戳全部设为无穷(表示未结束 或下一版本未结束修改本事务)
- 当t1在t2之前commit,当t2结束事务后,就会把比他先结束的A1的结束时间戳设置为他的开始时间戳,这样的话时间戳顺序就是A1 (0 - 2) A2 (2 - 无穷)
- 有一个新事务t3来的话 他的开始时间戳就是3 A1对他就是不可见的
- 他必须找到一个包含他事务号的区间的事务 才对他是可见的 也就是2 - 无穷,这个时候还不能确定可见的事务是否已提交 所以还需要维护一个事务状态表:
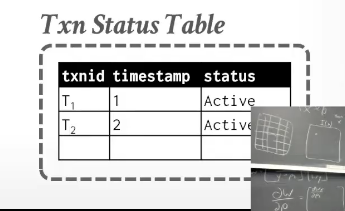
但是如果3读元组A的时候t2未提交 那么他依旧需要去看旧版本A1 而不是A2



写写冲突
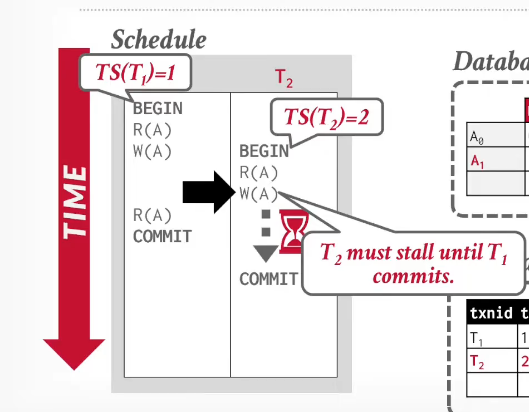
- 维护一条版本链(还有一个时间旅行的概念,但其实不怎么有用)
- 如果修改了一个数据 那么就插入这一个新的数据到本来旧数据的位置,将旧数据作为增量表通过指针连接,方便回滚以及事务隔离级别的查找(也有将新数据作为增量表的,可以对比两者优劣)
- 同一事务中如果更新一条数据,后再次更新多条数据或单条数据,最佳情况下应该只有一个版本
- 最难的是垃圾回收机制 因为很容易会有一些版本其实是永远不再看见的 应该被回收 其实应该有一个全局时间戳 用以清理目前一些无用的条目(版本低于该时间戳的都得被清理掉)
后续
后续内容大部分在分析oracle等sql的处理方法,就先跳过了,后续有需要再补充(但其实还有一个增量表的例子也挺有意思)
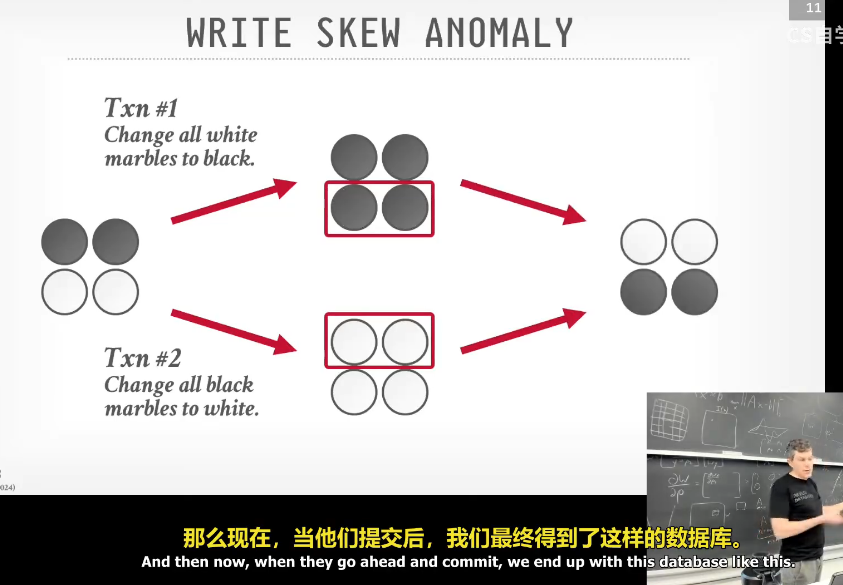
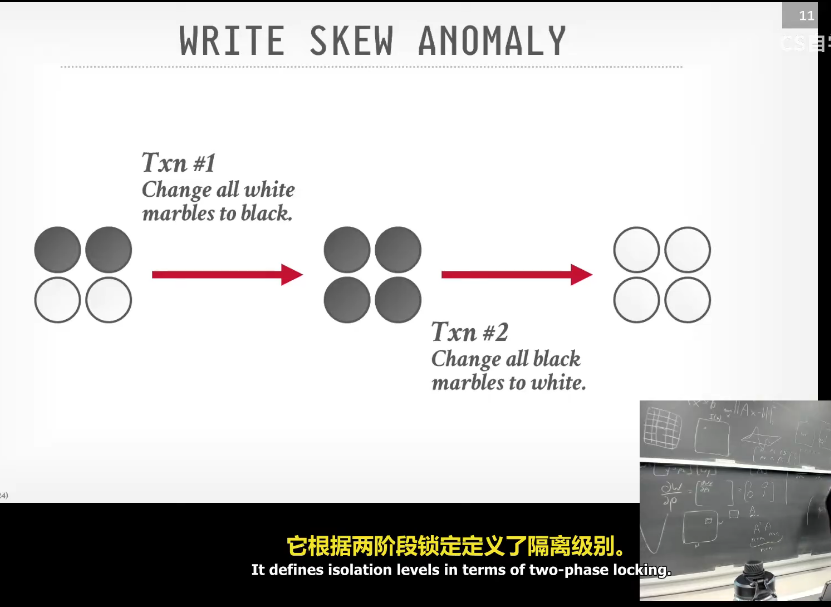
不一定可串行,因为修改是增量的。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 去远方!
评论



![[论文阅读]G-OLAP](http://aplainjane.github.io/article/3356482c/wallhaven-7jpjzv_1920x1080.png)
