
cyber小鲸——基于mediapipe、大模型融合的数字人
先鸽一会~

2025-10-30来收尾了
震撼,历经4个多月,居然还有人愿意回来填坑……
两个主要功能:对话和动捕,其实感觉对话算是非常普遍的一个功能了,主要还是动捕这一套流程比较有意思。
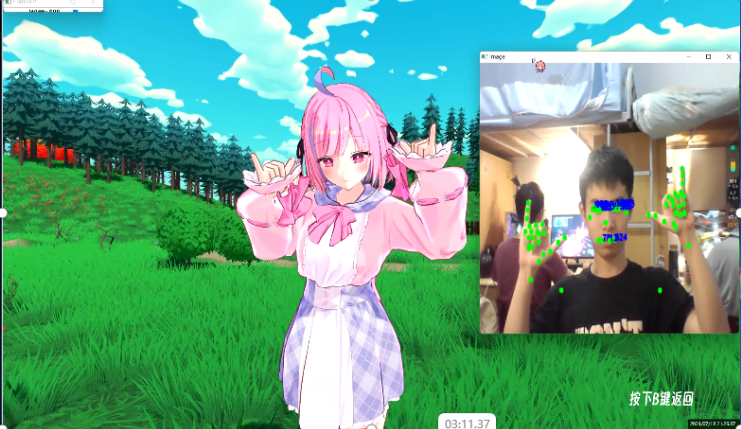
动捕面捕方案
项目基于mediapipe,深度训练后进行特征点提取具有极高精确度,并根据所提取的特征点对数字人的面部表情和动作作出相应的调整
优化使用UDP传输管道,实现捕捉数据的实时传输,确保动作和表情的同步性
优化EAR算法,针对不同用户的不同眼睛进行敏感度校参来实现更高精度的眼睛状态识别。
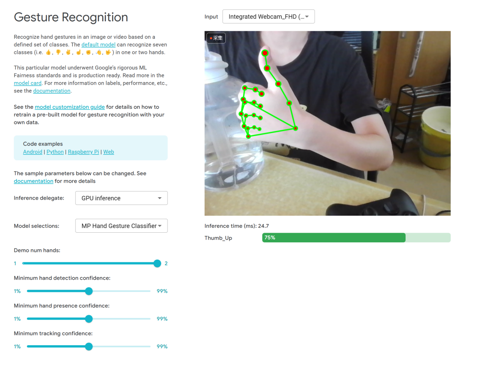
项目通过OpenCV,捕获摄像头视频流,将图像从BGR格式转换为RGB格式,便于MediaPipe处理。使用MediaPipe,对姿态、手部和面部关键点分别进行检测,同时在开发过程中,检测结果可以在python端预览。
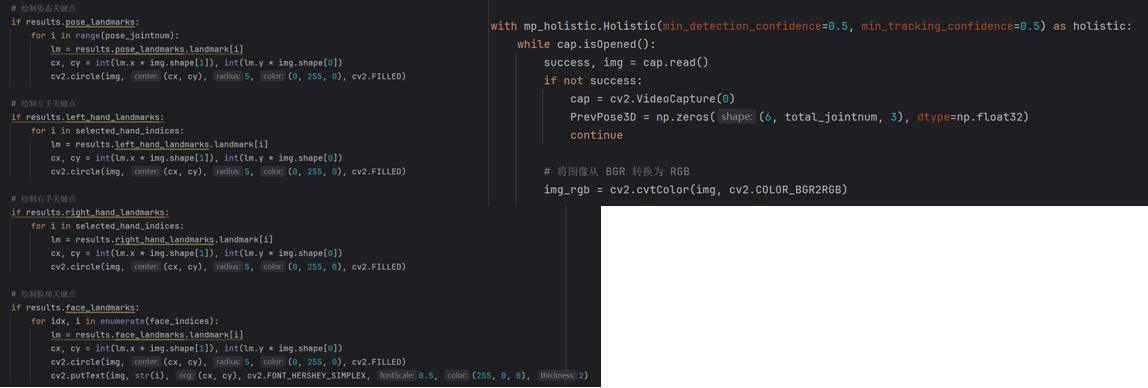
对于手部和面部,将检测到的关键点进行简化,保留对于操控虚拟数字人手指、嘴巴、眼睛等部位而言比较重要的关键点。

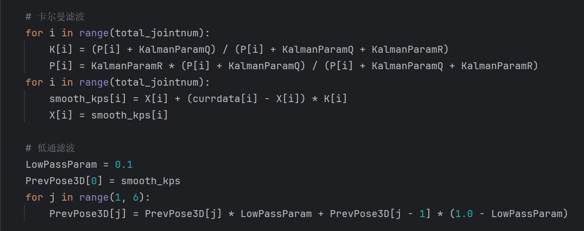
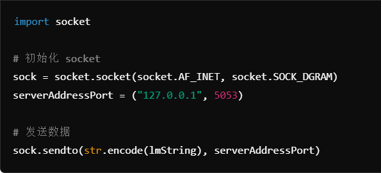
借助Socket实现通信。使用UDP协议,通过Socket将处理后的关键点数据发送到指定的服务器地址(在这里是本机)和指定的端口。为了提高关键点检测的稳定性和精度,采用了卡尔曼滤波和低通滤波技术对捕捉到的动作数据进行平滑处理。卡尔曼滤波:用于减少数据的抖动和噪声。低通滤波:进一步平滑数据,提高检测的稳定性。
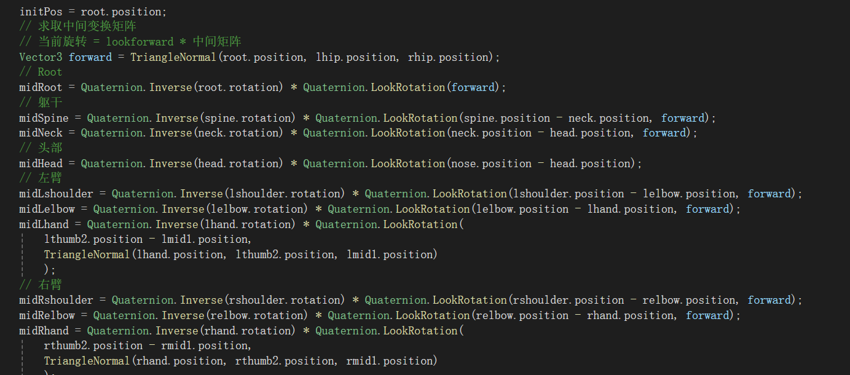
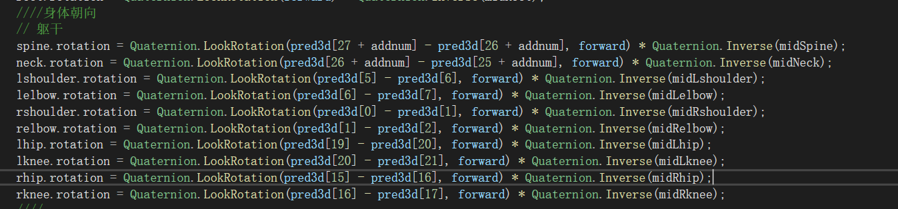
结果式——当前旋转角度 = lookforward * 中间矩阵
推导式——lookforward = 当前旋转角度(目标角度 ,当前朝向) * 中间矩阵的逆
当前旋转角度由python端mediapipe获取,使用udp进行传输由初始状态求中间矩阵的逆,代入结果式
表情
使用blendershape(模型一般自带)体现:使用眨眼检测算法——EAR,通过计算眼睛长宽比来检测是否闭眼。
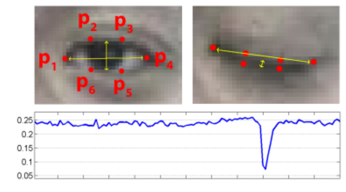
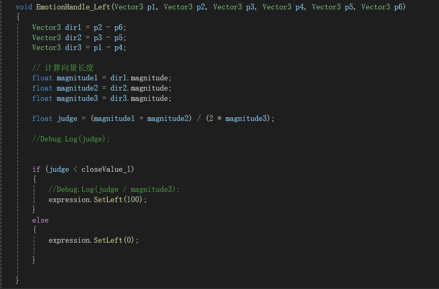
取三个特征点来计算嘴部张开的角度
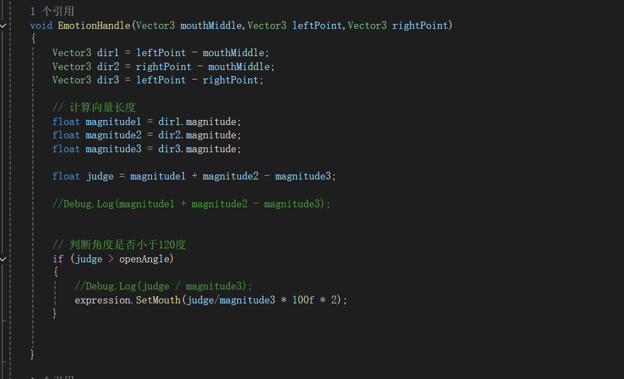
手势
通过骨骼关节点的旋转角度来体现(本来想用矩阵算,但是最终结果比较鬼畜)判断标准——手指与根节点的接近程度与肩宽之比(肩宽算是比较稳定不会变化的长度)
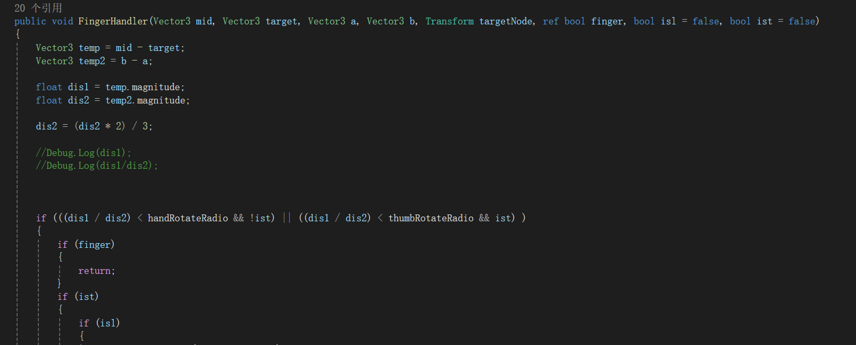
布料模拟
使用magica cloth2进行模拟



![[论文阅读]G-OLAP](http://aplainjane.github.io/article/3356482c/wallhaven-7jpjzv_1920x1080.png)
