
自动驾驶点云预测模型ViDAR融合知识图谱的初步尝试
前言
这个是针对于知识工程的学习与进一步实践,个人感觉难度挺高的,前后花费了大概有三周的时间,第一周主要是解决依赖的各种报错问题,第二周主要用在数据集的裁切和平台迁移上(这个主要受制于gpu的内存不够),第三周主要用在调优思路的探索和实践上,花了这么长时间感觉还是跟学校的课程安排有关,以及现在已经快接近五月了,保研人应该都懂……各种夏令营的事情和课程大作业搞得有点晕头撞向的,因此只能尽自己最大努力利用时间来完成这个课程实践,最后嘛还是有许多遗憾,但只能止步于此了……
过程
使用model art平台
模型链接:
https://github.com/OpenDriveLab/ViDAR
前置:
配置model art镜像

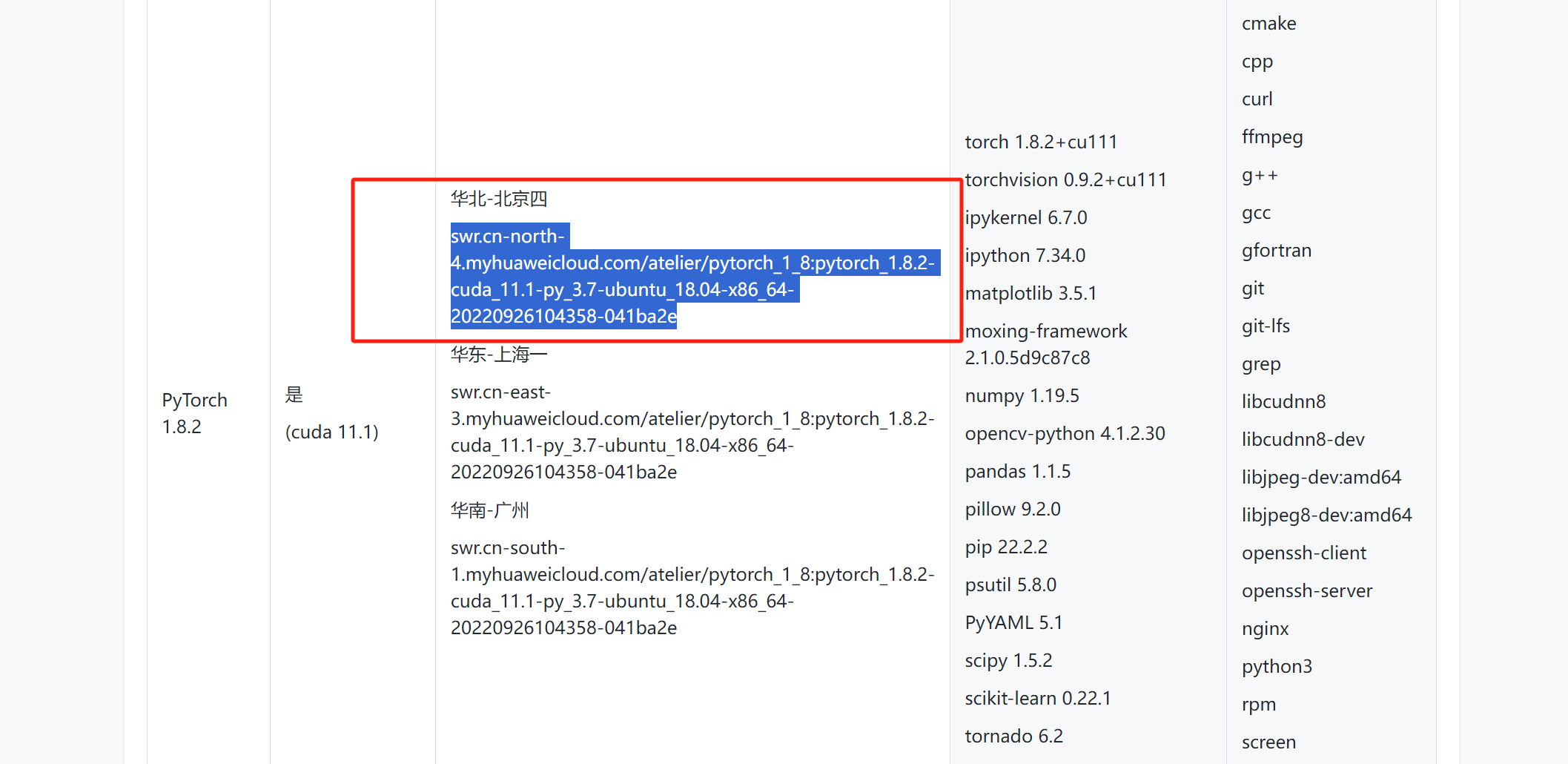
通过以上步骤进行镜像配置,就不过多赘述了,当时的解释md文件被我删除了……
遇到的问题以及解决方法
依赖报错问题:主要集中在numpy的版本上,因为model art本身要求的numpy版本较高,但是ViDAR又需要较低版本导致冲突,后面配置了一个脚本用于解决大部分问题:
vim install_deps.sh
然后:
# 设置清华源
PIP_SOURCE="-i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn"
# 临时移除 ModelArts SDK 以避免干扰
export ORIGINAL_PYTHONPATH=$PYTHONPATH
export PYTHONPATH=$(echo $PYTHONPATH | sed 's|/home/ma-user/modelarts-dev/modelarts-sdk||g')
# 打印环境信息
echo "Checking Python and PyTorch versions..."
python -c "import sys, torch; print('Python:', sys.version); print('PyTorch:', torch.__version__, 'CUDA:', torch.cuda.is_available())"
# 步骤 1:修复依赖冲突
echo "Fixing dependency conflicts..."
pip install numpy==1.23.5 --force-reinstall $PIP_SOURCE
pip install networkx==2.2 --force-reinstall $PIP_SOURCE
pip install pyasn1==0.6.1 --force-reinstall $PIP_SOURCE
pip install pandas==1.2.5 --force-reinstall $PIP_SOURCE # 确保 pandas 版本
# 步骤 2:处理“平台不支持”包,降级到兼容版本
echo "Fixing platform compatibility issues..."
pip install mmengine
pip install PyYAML==6.0 charset-normalizer==3.3.2 fonttools==4.38.0 kiwisolver==1.4.5 \
lxml==4.9.3 matplotlib==3.5.2 simplejson==3.19.2 MarkupSafe==2.1.5 \
cffi==1.16.0 greenlet==3.0.3 ijson==3.2.4 SQLAlchemy==2.0.30 \
--force-reinstall $PIP_SOURCE
# 步骤 3:安装 mmcv-full==1.4.0
echo "Installing mmcv-full==1.4.0..."
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html $PIP_SOURCE
# 步骤 4:安装 mmdet3d 剩余依赖
echo "Installing mmdet3d dependencies..."
pip install lyft_dataset_sdk nuscenes-devkit plyfile tensorboard numba==0.48.0 scikit-image==0.19.3 $PIP_SOURCE
pip install numpy==1.23.5 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.10.0/index.html -i https://pypi.tuna.tsinghua.edu.cn/simple
# 步骤 5:安装 mmdet==2.14.0 和 mmsegmentation==0.14.1
echo "Installing mmdet==2.14.0 and mmsegmentation==0.14.1..."
pip install mmdet==2.14.0 $PIP_SOURCE
pip install mmsegmentation==0.14.1 $PIP_SOURCE
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.1 # Other versions may not be compatible.
python setup.py install
cd ..
# 步骤 6:安装 detectron2 和其他依赖
echo "Installing detectron2 and other dependencies..."
pip install einops fvcore seaborn iopath==0.1.9 timm==0.6.13 typing-extensions==4.5.0 \
pylint ipython==8.12 matplotlib==3.5.2 numba==0.48.0 setuptools==59.5.0 $PIP_SOURCE
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git' $PIP_SOURCE
# 步骤 7:安装 ViDAR 和 chamferdistance
echo "Installing ViDAR and chamferdistance..."
if [ ! -d "ViDAR" ]; then
git clone https://github.com/OpenDriveLab/ViDAR
fi
cd ViDAR
mkdir -p pretrained
cd pretrained
wget https://github.com/zhiqi-li/storage/releases/download/v1.0/r101_dcn_fcos3d_pretrain.pth || echo "Pretrained model download failed, continuing..."
cd ../third_lib/chamfer_dist/chamferdist/
pip install . $PIP_SOURCE
cd ../../..
pip install matplotlib==3.5.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyparsing==2.4.7 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install kiwisolver==1.3.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --user prettytable==3.7.0
# 提示完成
echo "Installation complete. If errors occurred, check logs above."
# 可选:隔离环境(注释掉,需手动启用
# echo "If conflicts persist, consider creating a clean environment:"
# echo "conda create -n vidar_clean python=3.8"
# echo "conda activate vidar_clean"
# echo "Then rerun this script."然后就是喜闻乐见的一键解决问题了
chmod +x install_deps.sh
./install_deps.sh然后有两个地方需要修改:
之后到达vidar目录下:
CONFIG=ViDAR/projects/configs/vidar_pretrain/OpenScene/vidar_OpenScene_train_1_8_3future.py GPU_NUM=1
CONFIG=projects/configs/vidar_pretrain/OpenScene/vidar_OpenScene_mini_1_8_3future.py
GPU_NUM=1
./tools/dist_train.sh ${CONFIG} ${GPU_NUM}数据集
使用openxlab软件包。注:最高版本openxlab需要python≥3.8,因此需要创建一个虚拟环境安装
conda create -n openxlab python=3.9
pip install openxlab
openxlab login # 需要创建openxlab账号之后,创建access key再在这里登录
#我的AK/SK放在代码块外面
openxlab dataset download --dataset-repo OpenDriveLab/OpenScene --source-path /openscene-v1.1/openscene_sensor_mini_camera.tgz --target-path .
openxlab dataset download --dataset-repo OpenDriveLab/OpenScene --source-path /openscene-v1.1/openscene_sensor_mini_lidar.tgz --target-path .Access Key: wgakjbrzyyxljprb1b2z Secret Key: rnyq568lwdpayblrb744qdmxyg4xz19vo3b0azog
然后用上面的指令解压。大概占据硬盘空间170GB左右,因为要解压所以硬盘建议大概250-300GB
数据集解压后自动移动 MergedPointCloud 到目标路径:
可以运行脚本vim fix_mergedpointcloud.py
import os
import shutil
# 根目录路径(根据你实际目录修改)
bad_root = "ViDAR/data/openscene_v1.1/OpenDriveLab___OpenScene/openscene-v1.1/openscene_v1.1/sensor_blobs/mini"
correct_root = "ViDAR/data/openscene_v1.1/sensor_blobs/mini"
# 遍历所有 subdir
for subdir in os.listdir(bad_root):
full_bad_path = os.path.join(bad_root, subdir, "MergedPointCloud")
full_target_dir = os.path.join(correct_root, subdir)
if os.path.exists(full_bad_path):
target_path = os.path.join(full_target_dir, "MergedPointCloud")
print(f"Moving {full_bad_path} --> {target_path}")
os.makedirs(full_target_dir, exist_ok=True)
if os.path.exists(target_path):
print(f" - Skipping {target_path} (already exists)")
else:
shutil.move(full_bad_path, target_path)执行:python fix_mergedpointcloud.py
或者创建软连接
import os
bad_root = "ViDAR/data/openscene_v1.1/OpenDriveLab___OpenScene/openscene-v1.1/openscene_v1.1/sensor_blobs/mini"
correct_root = "ViDAR/data/openscene_v1.1/sensor_blobs/mini"
for sequence in os.listdir(bad_root):
bad_mp = os.path.join(bad_root, sequence, "MergedPointCloud")
correct_target_dir = os.path.join(correct_root, sequence)
correct_link_path = os.path.join(correct_target_dir, "MergedPointCloud")
if os.path.exists(bad_mp):
if not os.path.exists(correct_target_dir):
print(f"路径不存在,创建中:{correct_target_dir}")
os.makedirs(correct_target_dir)
if not os.path.exists(correct_link_path):
print(f"创建软链接:{correct_link_path} -> {bad_mp}")
os.symlink(os.path.abspath(bad_mp), correct_link_path)
else:
print(f"已存在:{correct_link_path}")openscene_metadata_mini.tgz可以下载本地再直接上传
最后:
python tools/collect_nuplan_data.py mini训练的一些报错
ninja报错
RuntimeError: Ninja is required to load C++
解决:从源码构建并本地安装
下载和构建 Ninja:
克隆 Ninja 官方仓库:
bash
git clone <https://github.com/ninja-build/ninja.git>
cd ninja
python configure.py --bootstrap这会生成
ninja二进制文件。
创建本地目录并移动文件:
创建
~/bin目录(如果不存在):bash
mkdir -p ~/bin将
ninja二进制文件移动到~/bin:bash
mv ninja ~/bin/
更新 PATH 环境变量:
临时添加至当前会话:
bash
export PATH=~/bin:$PATH
验证安装:
- 运行
ninja --version检查是否成功。
- 运行
crypt.h报错解决:
步骤 1:确认 glibc-2.27 源码
确保你已从 GNU FTP 服务器 下载并解压了 glibc-2.27.tar.xz 文件。如果未下载,使用以下命令:
ruby
wget <https://ftp.gnu.org/gnu/glibc/glibc-2.27.tar.xz>
tar -xJf glibc-2.27.tar.xz确认解压后生成了
glibc-2.27目录,并包含include子目录。
步骤 2:复制所有头文件
将 glibc-2.27/include 目录下的所有头文件复制到你的本地 ~/include 目录,以确保所有依赖头文件(如
features.h、stdint.h等)都可用:bash
mkdir -p ~/include
cp -r glibc-2.27/include/* ~/include/这将复制包括
crypt.h在内的所有头文件到 ~/include,确保编译器能找到所有必需的依赖。
步骤 3:设置包含路径
设置
CPLUS_INCLUDE_PATH环境变量,确保编译器优先搜索 ~/include 目录:bash
export CPLUS_INCLUDE_PATH=~/include:$CPLUS_INCLUDE_PATH验证环境变量设置:
bash
echo $CPLUS_INCLUDE_PATH应包含
~/include。
步骤 4:检查系统头文件
首先,检查你的环境中是否已有必要的头文件:
运行
ls /usr/include/crypt.h
查看是否已有
crypt.h
。如果存在,尝试使用系统编译器:
- 运行
export CC=/usr/bin/gcc和export CXX=/usr/bin/g++。 - 然后取消设置
CPLUS_INCLUDE_PATH:unset CPLUS_INCLUDE_PATH。 - 重新运行训练脚本:
./tools/dist_train.sh ${CONFIG} ${GPU_NUM}。
- 运行
GLIBCXX_3.4.29报错
参考:
[如何解决version `GLIBCXX_3.4.29‘ not found的问题_glibcxx not found-CSDN博客](https://blog.csdn.net/weixin_39379635/article/details/129159713)
解决:
ImportError: /home/ma-user/anaconda3/envs/vidar/lib/libstdc++.so.6: version `GLIBCXX_3.4.29' not found
1、使用指令先看下系统目前都有哪些版本的
strings /home/ma-user/anaconda3/envs/vidar/lib/libstdc++.so.6 | grep GLIBCXX
发现只到3.4.22
2、来查看当前系统中其它的同类型文件,
sudo find / -name "libstdc++.so.6*"
找到一个版本比较高的 /home/ma-user/anaconda3/envs/vidar/lib/libstdc++.so.6.0.29
查看
strings /home/ma-user/anaconda3/envs/vidar/lib/libstdc++.so.6.0.29 | grep GLIBCXX
有了3.4.29
3、复制到指定目录并建立新的链接
复制
sudo cp /home/ma-user/anaconda3/envs/vidar/lib/libstdc++.so.6.0.29 /home/ma-user/anaconda3/envs/vidar/lib/
删除之前链接
sudo rm /home/ma-user/anaconda3/envs/vidar/lib/libstdc++.so.6
创建新的链接
sudo ln -s /home/ma-user/anaconda3/envs/vidar/lib/libstdc++.so.6.0.29 /home/ma-user/anaconda3/envs/vidar/lib/libstdc++.so.6验证
strings /home/ma-user/anaconda3/envs/vidar/lib/libstdc++.so.6 | grep GLIBCXX
有了3.4.29
另:如果是/usr/lib/x86_64-linux-gnu/libstdc++.so.6报错,使用:
export LD_LIBRARY_PATH=$CONDA_PREFIX/lib:$LD_LIBRARY_PATH
GPU爆内存
cuda out of memory
只训练mini数据集的一部分,注意留的数据meta_datas里的文件夹名字和sensor_blobs里文件夹名对应
fsspec 与 Python 3.8 兼容性问题
TypeError: ‘type’ object is not subscriptable
解决方法:降低到fsspec可以兼容3.8的版本
pip install fsspec==2025.3.0
ViDAR模型实现分析
模型架构概述
ViDAR(Visual Point Cloud Forecasting enables Scalable Autonomous Driving)是一个基于BEVFormer架构的模型,专注于自动驾驶场景中的视觉点云预测。从 vidar_transformer.py 文件可以看出,它主要实现了一个预测变换器(PredictionTransformer)。
核心组件
- PredictionTransformer :
- 这是ViDAR的核心组件,用于从多帧BEV特征预测下一帧的BEV特征
- 使用了自定义的解码器来处理时序信息
- 注意力机制 :
- 时间自注意力(TemporalSelfAttention):处理时间维度上的信息
- 空间交叉注意力(MSDeformableAttention3D):处理3D空间中的信息
- 自定义可变形注意力(CustomMSDeformableAttention):用于处理特征对齐
项目结构
项目结构显示ViDAR是基于BEVFormer进行扩展的:
projects/
├── configs/
│ ├── base/
│ ├── bevformer/
│ ├── vidar_finetune/ # ViDAR微调配置
│ └── vidar_pretrain/ # ViDAR预训练配置
└── mmdet3d_plugin/
├── bevformer/ # BEVFormer相关模块
├── core/ # 核心评估和功能模块
├── datasets/ # 数据集处理
├── dd3d/ # 3D检测相关模块
└── models/ # 模型定义
与BEVFormer的关系
ViDAR似乎是在BEVFormer基础上的扩展,专注于未来帧预测:
- BEVFormer主要关注多视角图像到BEV表示的转换
- ViDAR则进一步关注BEV表示的时序预测,实现对未来场景的预测
调优思路
融合Nskg
写在前面:
这个项目其实没有想象的复杂,大概如下:
ViDAR模型似乎是一个基于BEVFormer架构的3D检测/分割模型,它利用MMDetection3D框架实现,支持多视角图像到BEV表示的转换。该模型具有灵活的配置系统、插件扩展能力和完善的训练功能。
那么有了以上信息就好做了,首先学习下MMDetection3D的使用方法,Vidar只不过在上面多封装了一层,那么这一层应该也可以写插件进行拓展
核心目录:
- 模型定义文件(可能在 projects/mmdet3d_plugin/bevformer/ 目录下)
- 配置文件(通过命令行参数 config 指定)
- 自定义训练函数 custom_train_model 的实现
论文1:nuScenes Knowledge Graph (nSKG)
nuScenes Knowledge Graph (nSKG) 文章的内容可以很好地融入对 ViDAR: Visual Point Cloud Forecasting 模型的理解和调优中,尤其是在以下几个方面:
- 丰富场景表示:nSKG 提供了 nuScenes 数据集的综合语义表示,包含交通场景中的实体(如车辆、行人、车道、交通信号灯)和它们之间的语义与空间关系。这可以增强 ViDAR 的输入数据,改善其点云预测和下游任务(如感知、规划)的性能。
- 数据处理改进:nSKG 的结构化数据(以知识图谱和 PyTorch Geometric 格式提供)可以直接用于 ViDAR 的数据管道,减少数据预处理的工程负担。
- 模型架构增强:nSKG 的异构图表示可以与 ViDAR 的 Transformer 或 BEVFormer 模块结合,引入图神经网络(GNN)来处理语义关系,提升预测的鲁棒性和可解释性。
- 调优方向:利用 nSKG 的丰富上下文(如车道拓扑、代理关系),可以优化 ViDAR 的超参数、数据增强策略和损失函数,特别是在处理复杂交通场景时。
实际修改:
ViDAR项目集成nSTP的工作总结
根据当前代码库,我将总结从初始状态到现在为止,为了集成nSTP(Neural Scene-Time Priors)所做的工作。
1. 核心文件创建
1.1 nSTP编码器模块
文件路径: ViDAR\projects\mmdet3d_plugin\bevformer\modules\nstp_encoder.py
主要功能:
- 创建了
NSTPEncoder类:使用图神经网络(GraphSAGE或GAT)处理nSTP图数据 - 创建了
NSTPEnhancer类:将nSTP特征与BEV特征融合,通过注意力机制增强BEV特征
import torch |
1.2 nSTP数据处理组件
文件路径: ViDAR\projects\mmdet3d_plugin\datasets\pipelines\nstp_transform.py
主要功能:
- 创建了
ProcessNSTPGraph类:处理nSTP图数据,确保格式正确并转换为PyTorch张量
import torch |
2. 现有文件修改
2.1 数据集类修改
2.1.1 NuScenes数据集
文件路径: ViDAR\projects\mmdet3d_plugin\datasets\nuscenes_vidar_dataset_v1.py
主要修改:
- 添加了nSTP相关参数:
use_nstp,nstp_path - 实现了
_load_nstp_data方法:加载nSTP图数据文件 - 修改了
get_data_info方法:将nSTP数据添加到样本信息中
#---------------------------------------------------------------------------------# |
2.1.2 NuPlan数据集
文件路径: d:\git_clone\ViDAR\projects\mmdet3d_plugin\datasets\nuplan_vidar_dataset_v1.py
主要修改:
- 与NuScenes数据集类似,添加了nSTP支持
- 实现了特定于NuPlan数据集的nSTP数据加载和处理逻辑
2.2 模型头部修改
文件路径: ViDAR\projects\mmdet3d_plugin\bevformer\dense_heads\vidar_head_v1.py
主要修改:
- 添加了nSTP相关参数:
use_nstp,nstp_encoder_cfg,nstp_enhancer_cfg - 集成了nSTP编码器和增强器到模型头部
- 修改了前向传播逻辑,处理nSTP特征
#---------------------------------------------------------------------------------# |
2.3 ViDAR检测器修改
文件路径: ViDAR\projects\mmdet3d_plugin\bevformer\detectors\vidar.py
主要修改:
- 修改了
forward_train方法:处理nSTP特征,并解决了元组类型问题 - 修改了
forward_test方法:支持测试时使用nSTP特征
关键修改部分:
def forward_train(self, **kwargs): |
3. 配置文件修改
3.1 OpenScene配置
文件路径: ViDAR\projects\configs\vidar_pretrain\OpenScene\vidar_OpenScene_mini_1_8_3future_nstp.py
主要修改:
- 添加了nSTP相关配置:启用nSTP,设置数据路径
- 修改了数据处理流程,添加了nSTP数据处理组件
- 配置了nSTP编码器和增强器参数
# nSTP配置 |
3.2 NuScenes全集配置
文件路径: ViDAR\projects\configs\vidar_pretrain\nusc_fullset\vidar_nstp_nusc.py
主要修改:
- 基于基础配置,添加了nSTP支持
- 配置了nSTP数据路径和处理逻辑
_base_ = ['./vidar_full_nusc_1future.py'] |
4. 其他辅助修改
4.1 数据集注册
文件路径: d:\git_clone\ViDAR\projects\mmdet3d_plugin\datasets\__init__.py
主要修改:
- 导入并注册了nSTP相关模块:
NSTPEncoder,NSTPEnhancer
from .nstp_encoder import NSTPEncoder, NSTPEnhancer |
5. 过程中的好多错误

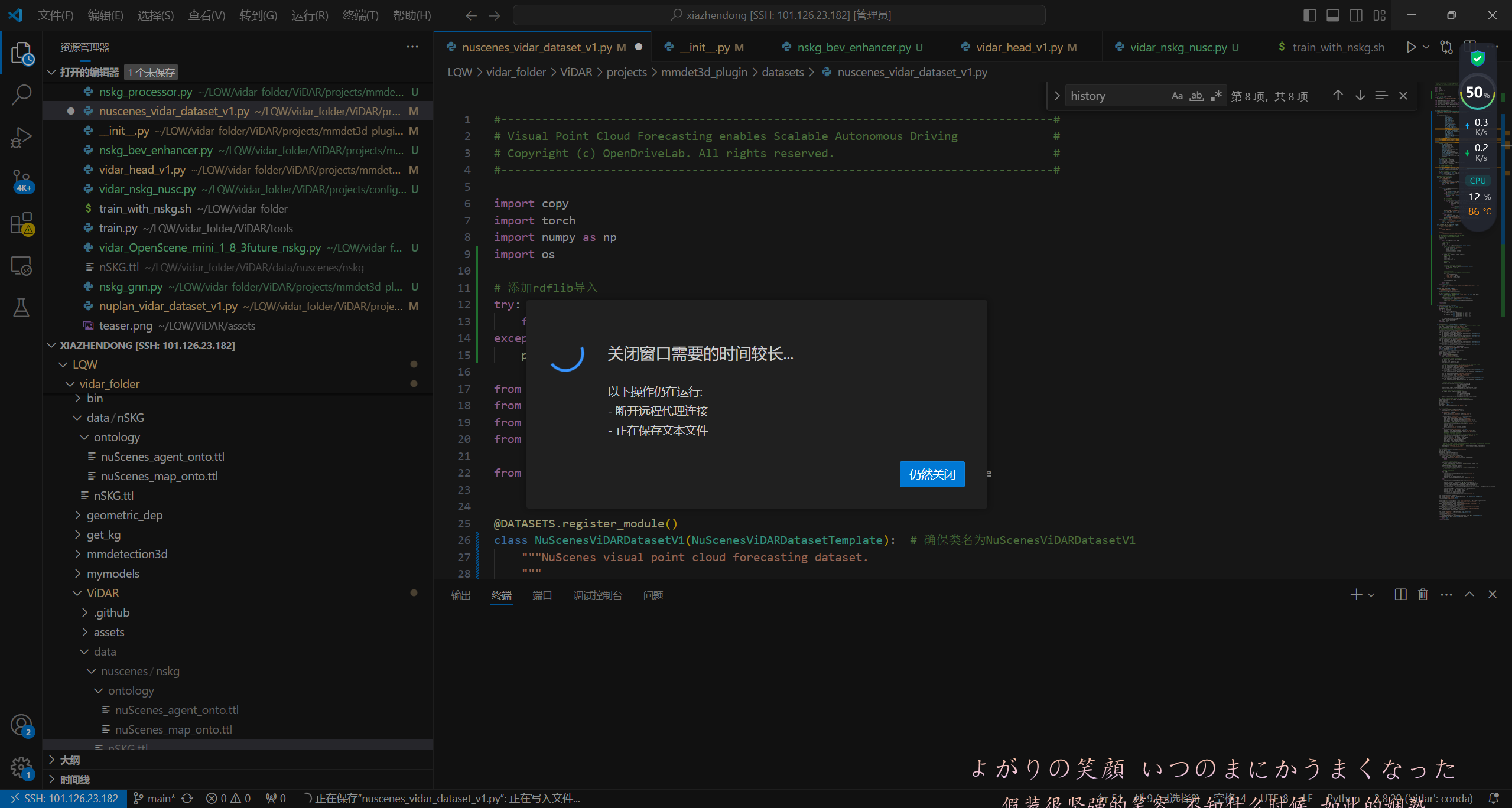
首先是数据集nSKG不能用,用了会出现这个问题:

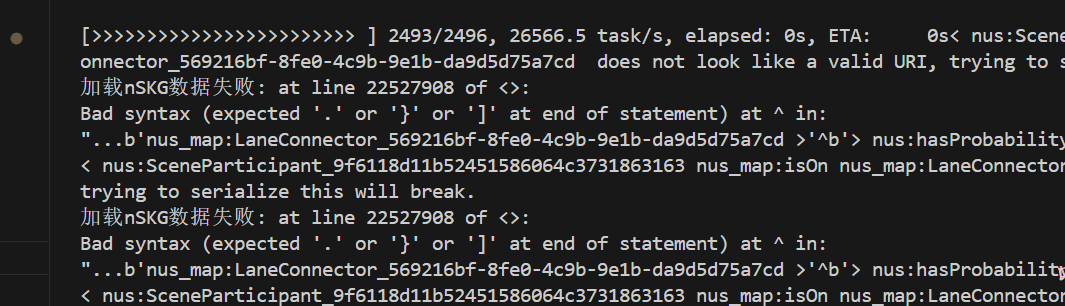
然后进而导致:
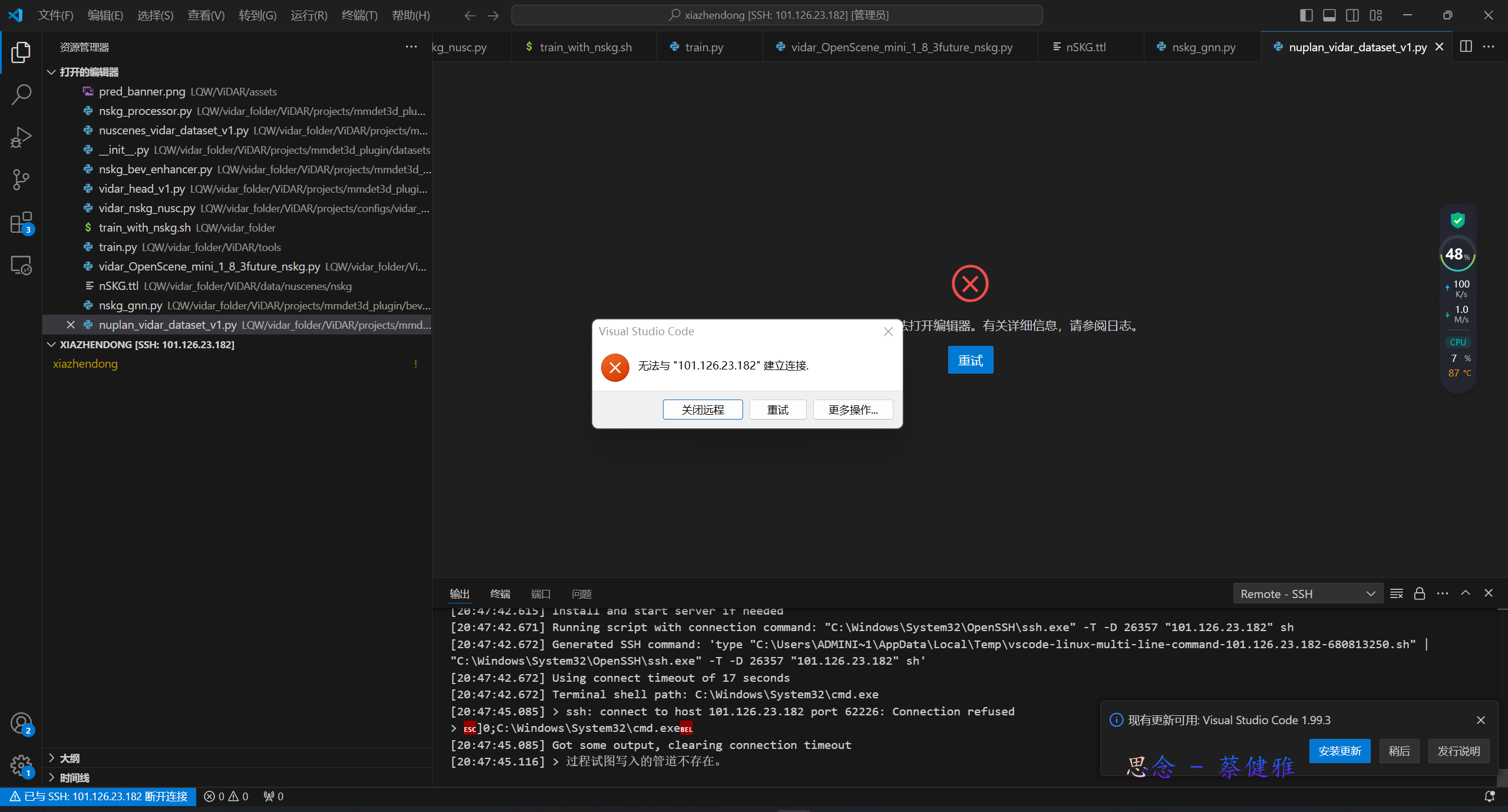
然后对他做细致处理的话,其实也可以,但是我写的代码处理不了:
所以最后选择使用nSTP,因为在nuScenes Knowledge Graph发现了nSTP是对nSKG的拓展,而且可以直接拿来训练,因此修改代码适配:


最后结果,可以正常读取nSTP数据文件:
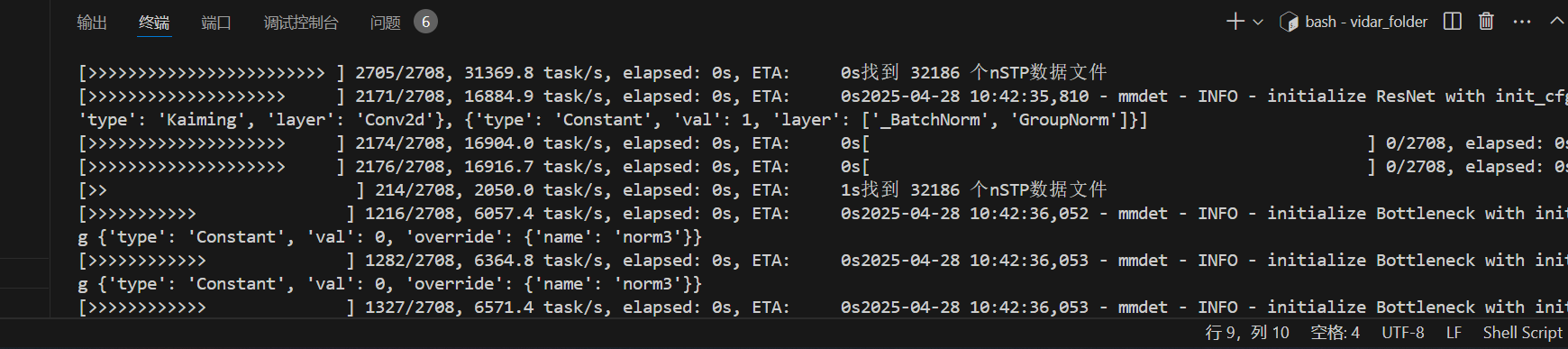
但是……爆内存了:
写到这里的时候刚修复了一小点bug,目前仍然在服务器上跑着……
然后最后贴一张饱受折损的服务器合照(感谢罗勇老师)
6. 最后总结
nSTP集成工作主要包括以下几个方面:
- 数据处理:创建了nSTP图数据的加载和处理逻辑,支持从.pt文件中读取图结构数据
- 特征提取:实现了基于图神经网络的nSTP编码器,提取图结构中的时空特征
- 特征融合:实现了nSTP特征与BEV特征的融合机制,通过注意力机制增强BEV特征
- 模型集成:将nSTP模块集成到ViDAR模型中,修改了前向传播逻辑
- 配置支持:添加了nSTP相关配置,支持灵活开启/关闭nSTP功能
这些修改使ViDAR模型能够利用nSTP提供的场景结构和时间演化信息,增强了模型对动态场景的理解能力,特别是在预测未来帧方面。
然后我们完成的工作:
- 完成环境配置,解决冲突依赖问题
- 完成数据集的读取与训练问题
- 完成对vidar的修改以加入nSTP数据集来调优
- 修复原本的pytouch问题
- 目前仍然在服务器上跑着,估计还有不少后续的训练问题需要修改……但是没时间了



![[论文阅读]G-OLAP](http://aplainjane.github.io/article/3356482c/wallhaven-7jpjzv_1920x1080.png)
